【经验】如何优化AD/ADAS的SoC AI性能?

近年,随着深度学习(DeepLearning)人工智能(AI)技术的进步,我们的生活中出现了许多直接有益的应用场景,例如自动翻译精度的提升和根据消费者喜好的个性化推荐。截至2023年,AI在某些领域已经成为产品和服务中不可或缺的应用,其中之一就是自动驾驶(AD)和先进驾驶辅助系统(ADAS)。
以深度神经网络(DNN)为代表的最新人工智能模型的处理需要大规模的并行计算,因此在PC开发中通常使用通用的GPU进行并行计算。 另一方面,用于AD和ADAS的SoC多数搭载了专用电路(以下简称加速器),实现了低功耗和高性能的DNN处理。 然而,在SoC开发的早期阶段,确认搭载的加速器能否在实际所需的DNN中提供足够的性能通常并不容易。性能比较的指标常常使用加速器设计上的最大计算性能TOPS(Tera Operations Per Second)值,或者其与运行时消耗的功率相除得到的TOPS/W值。然而,由于加速器是针对特定处理的专用设计(*1),即使TOPS值足够高,在实际所需的DNN中也可能由于存在无法高效处理的计算或数据传输带宽不足等问题而无法提供足够的性能。 此外,加速器的功率增加可能导致整个SoC的功耗超过可接受的范围。
(*1) 专用设计:虽然使用通用GPU作为加速器也是可能的,但处理特定任务的硬件,可以在较小的电路规模和功耗下获得更高的处理性能。例如瑞萨的车载SoC R-Car V3H、R-Car V3M和R-Car V4H搭载的加速器具有专为处理DNN中使用卷积操作进行特征提取的卷积神经网络(CNN)任务而设计的结构。
随着SoC开发的深入,由于性能不足或功耗过大等原因而进行设计变更的难度普遍增加,对SoC开发进度和开发成本的影响也随之增加。因此,在开发面向车载AI设备的SoC时,确认搭载的加速器能否在实际顾客产品中所需的DNN中提供足够的性能,并且功耗是否在可接受范围内,已成为迫切的问题。
面向AD/ADAS的一般AI开发流程
在解释如何解决上述问题之前,先简单介绍一下AD/ADAS的AI开发流程。 下面的图1展示了在AD/ADAS中以软件为核心,并包括部分SoC开发的AI开发流程的示例。
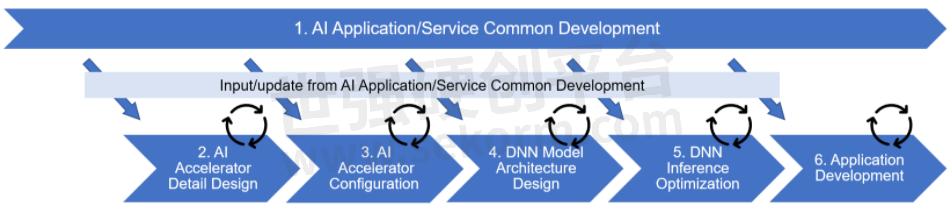
图1:AD/ADAS中AI开发流程的例子
图1将整个开发工作分为六个阶段,其中第2和第3阶段为SoC电路设计,其他第1和第4-6阶段为软件开发。 下面给出了每个阶段的工作概述。
第一阶段AI Application/Service Common Development,利用PC和云环境,以应对市场需求和技术趋势,开发面向AD/ADAS的AI应用程序和服务。
第二阶段AI Accelerator Detail Design,涵盖了构成加速器硬件的部件设计,如计算单元、内部存储器和数据传输单元。
在第三阶段AI Accelerator Configuration中,第二阶段中设计的组件被组合起来,以优化面积、功率和性能之间的权衡,同时确定加速器在SoC中的配置以实现各自的设计目标。
在第四阶段DNN Model Architecture Design中,在第三阶段中确定的加速器配置被用来优化每个用于客户产品的DNN网络的结构。
第五阶段DNN Inference Optimization将针对经过第四阶段结构优化的每个网络进行适用于加速器的代码生成,并进行精度和处理时间的详细评估。同时,将对代码和模型数据进行优化,以提高性能。
第六阶段Application Development将使用第五阶段中优化的代码和模型数据,将AI处理部分嵌入到实际的自动驾驶等处理中,并进行应用的实现和评估。
瑞萨的工作
在上一节所示的AD/ADAS中的AI开发流程中,判断实际使用的DNN是否能够在所配备的加速器上提供足够的性能,通常需要在决定加速器配置的第三阶段AI Accelerator Configuration中进行决策。
传统上,在这一阶段的决策是通过使用类似加速器的现有SoC进行的基准测试结果来估计的,但对于因增加或改变功能而与现有SoC规格不同的部分,无法获得基准测试结果,因此无法通过高度精确的估计来确定是否能达到设计目标。
瑞萨通过使用PPA Estimator (PPA是Performance, Power, Area的首字母)而不是现有的SoC基准测试来解决这个课题。PPA Estimator通过使用反映加速器每个组件设计的性能和功率计算模型,使性能和功耗在加速器配置最终确定之前得到估算。具体来说,列出可能的加速器配置(可改变的加速器参数的组合,如处理单元的数量和内部存储器的容量)进行评估,选择其中一个配置并与要评估的一个DNN一起输入PPA Estimator中,以获得所需的执行时间和功耗。然后,可以针对所需评估的加速器配置和DNN的数量进行重复操作,收集数据,并找到最佳的加速器配置。如此,不仅可以确定一个特定的加速器配置和DNN组合是否有足够的性能,而且还可以收集广泛的数据并从中选择最佳加速器配置。
此外,为了使第三阶段AI Accelerator Configuration更加有效,瑞萨还通过将从PPA Estimator执行结果中获得的信息反馈给目标DNN的网络模型,并行改进软件方面的工作,也就是进行硬件-软件联合设计(co-design)。AI Accelerator Configuration阶段的工作流程如下图2所示。
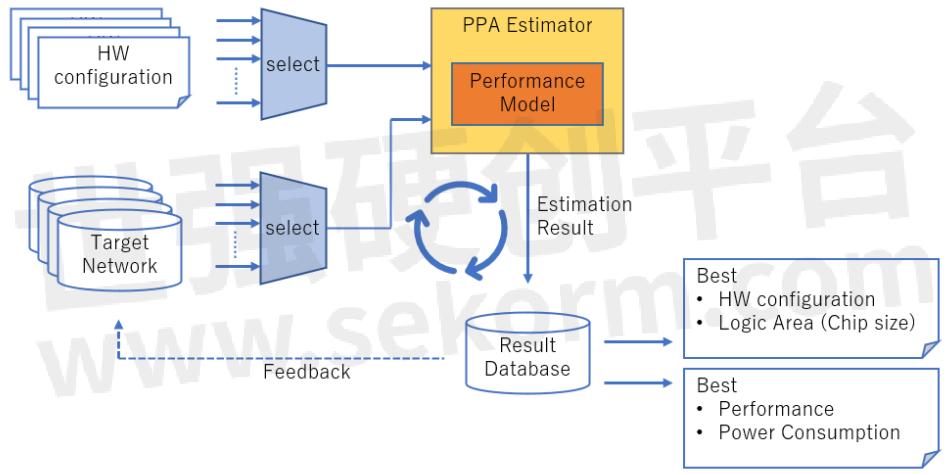
图2:AI Accelerator Configuration工作流程
瑞萨已开始将PPA Estimator应用于从2023年开始的一些带有AI处理加速器的AD/ADAS的SoC的开发中,并计划逐步扩大应用范围。瑞萨将利用PPA Estimator的高度精确性能寻找最佳配置以开发高性能、低功耗的车载AI加速器。
- |
- +1 赞 0
- 收藏
- 评论 0
本文由上山打老虎转载自RENESAS 官网,原文标题为:面向AD/ADAS的SoC的AI性能优化,本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
相关推荐

【经验】SOC CSU1181用于高精度称重设备时提高AD性能的几处PCB重点设计注意事项
CSU1181芯片是芯海科技推出的一个8位RISC架构的高性能单片机,集成了24Bit高精度ADC和LCD显示模块。只需几个简单的外围器件即可正常工作。然而对于高精度称重设备,特别是两万点以上精度的设备,电路及PCB设计极其重要,合理的设计可以有效提高称重设备的整体性能。

【经验】R-Car H3/H3N/M3 SoC芯片的AVS模块介绍及寄存器的配置
Renesas推出驾驶安全辅助系统和车载信息娱乐系统的第三代R-Car SoC芯片,内核方面使用的是Cortex-A57 CPU、Cortex-A53 CPU和Cortex-R7,主要面向无人驾驶、智能辅助驾驶、车机、仪表和ADAS等应用场景,并以其强大的算力和丰富的外设资源赢得了广大车厂和Tier 1的认可。本文将介绍瑞萨R-Car H3/H3N/M3的AVS模块介绍及寄存器的配置。

【经验】车规级SoC R CAR V3H2平台端工具链转换前 mobilenetv2.onnx浮点模型推理验证
RENESAS 车规级SoC R CAR V3H2平台上推理模型前,我们需要训练好自己的模型,目前通常采用迁移调优模型方式形成满足需求的浮点模型,并验证浮点模型的精度,耗时等性能,本文在ubuntu上用python推理浮点mobilenetv2.onnx模型。我们根据链接在公版的mobilenetv2模型基础上,迁移调优学习了自己采集的图片数据形成了自己要求的mobilenetv2.onnx模型。

【产品】低功耗全高清ADAS专用低功耗SoC芯片SGKS6802
森国科SGKS6802是一款针对高级辅助驾驶(ADAS)、流媒体后视镜、夜视系统、透雾透霾及图形图像识别与处理等产品开发的ADAS专用低功耗SoC芯片,1080P@30fps+720P@30fps双路码流H.264编码及高质量的ISP处理。

REF66012 – 参考设计 ADAS SoC用 PMIC解决方案
描述- 本资料介绍了ROHM公司为ADAS SoC设计的PMIC(电源管理集成电路)解决方案。方案包括BD96801Q09-CE2四通道DC-DC转换器和BD9S303MUF-CE23A同步降压转换器,旨在提供高效率和高可靠性。该方案适用于智能前视摄像头(IFC),集成200万像素摄像头和多毫米波雷达,支持L2级前向ADAS功能。它采用Horizon Journey2芯片和Infineon TRAVEO II系列CYT4BF微控制器,实现AEB、ACC等功能。此外,还提供了详细的规格和应用说明。
型号- BD96801Q09-CE2,BD9S303,BD9S303MUF-CE2,BD96801Q09,BD96801,BD9S303MUF

SOC系列芯片PCB设计建议
描述- 本文主要针对芯海科技SOC系列芯片的PCB设计提供指导,包括提高ESD性能、提升AD性能以及抗RI性能的方法。文章详细介绍了如何通过电路设计、电容接法、晶振电路布局等手段来优化PCB设计,以提升产品性能并满足严格的EMC测试标准。
型号- SOC

电子秤产品上用了芯海的SOC芯片,切换ADC通道后,须丢弃多少笔AD数值才稳定?
切换AD通道后,须丢弃前三笔转换的AD值,以确保转换的数值正确性。
健康体脂秤上用了芯海的SOC芯片,在高速输出速率时,为何有时会没有AD值输出?
模拟信号输入端的低通滤波器电容不能太大,我们建议使用47pf

【产品】 瑞萨第三代汽车级SOC RCAR-M3带你走进自动驾驶时代
瑞萨电子推出第三代Rcar系列芯片,致力于高级安全(智能)驾驶系统和车载娱乐系统,建立一个完善的无人驾驶领域半导体的技术平台。其中新的Rcar-M3成员(SOC),提供ARM双核cortex-A57以及4核cortex-A53的高CPU性能、3D图像识别处理引擎,符合ISO 26262(ASIL-B)的安全等级,支持系统级封装(SiP)集成高速缓存,功能完善,完美支持先进驾驶辅助系统的开发设计。

How to Build Together a Safe and Efficient AD & ADAS Central Computing Solution
Should RENESAS stop here and call it a success? Clearly no! Progress has no limits and by working together we ensure to constantly update our understanding of how autonomous systems of tomorrow will be and anticipate that by providing state-of-the-art processing solutions that would bring them successfully to the mass market.

【产品】瑞萨新一代SOC R-Car V3H,专为自动驾驶前置摄像头应用
瑞萨开发了专门针对前置摄像头应用的SoC——R-Car V3H,集成了专门针对图像处理的功能单元,它比R-Car V3M在视觉处理方面的性能提高了5倍,并只有0.3瓦的超低功耗,更好的适应自动驾驶的需求。

【产品】全新开放式平台,加大对ADAS及自动驾驶的支持
新型R-Car V3M SoC符合ISO26262功能安全标准,为视觉处理提供了低功耗硬件加速功能,还配有内置图像信号处理器。

【经验】使用瑞萨SoC R CAR V3H2 cnn工具链实现onnx模型转caffe模型的实操
R CAR V3H2 的cnn神经网络模块需要运行int16的定点模型,而onnx模型首先需要通过cnn工具链转成caffe模型,然后再转成端侧的可执行模型,本文使用瑞萨的cnn工具链实现onnx模型转caffe模型。

【经验】SoC R CAR V3H2 cnn模型转换后执行以及benchmark过程实操指南
RENESAS SoC R CAR V3H2 cnn模型转换后的输出文件有bcl和.pb 2类,都是可以在端侧执行的,本文记录.pb的推理输出以及benchmark过程实操及解析。

【经验】SoC R CAR V3H2 端侧推理输出的rcar_output.npy数据查看方法
RENESAS R CAR V3H2 端侧推理输出的数据有cvs格式,总共512个输出,同时把cvs数据转化为npy格式保存为一个rcar_output.npy文件,那我如何查看这些数据呢,本文记录数据查看方法。

电子商城

品牌:SILICON LABS
品类:Wireless Gecko SoC
价格:¥8.1764
现货: 102,628
品牌:SILICON LABS
品类:Mighty Gecko Multi-Protocol Wireless SoC
价格:¥27.0929
现货: 90,767

品牌:SILICON LABS
品类:Wireless Gecko SoC
价格:¥10.4994
现货: 50,699
现货市场

授权代理品牌:集成电路
























































授权代理品牌:分立元件






































授权代理品牌:接插件及结构件













授权代理品牌:部件、组件及配件




























授权代理品牌:电源及模块





授权代理品牌:电子材料














授权代理品牌:仪器仪表及测试配组件




授权代理品牌:电工工具及材料






授权代理品牌:机械电子元件








授权代理品牌:加工与定制












登录 | 立即注册
提交评论