MediaPipe—脸部、手掌及人体姿态特征检测


引文
“大家不要紧张,我本身呢是个汽车维修员,随身有个扳手是很正常的...”
虽然我们传感器似乎和当前的话题没有直接关系,但是本着能提供被检物体某种特性信号的都是传感器的理念,尤其与其相关的设备正在我们的产线上发挥着重要作用的情况下,关注和留意这些日新月异的事物就正常不过了。不如我们定义一个叫“软件传感器”的?
既然我们提到了图像处理,不妨多说一些,这里关于MediaPipe这个工具包,借用它,我们可以很容易实现面部、手掌,人体姿态特征等的识别和应用。小编尽可能提供这个工具包中相关功能的一些测试代码。
Mediapipe 是由 Google 开发并开源的一个多模态机器学习框架,广泛应用于实时的计算机视觉任务。该框架提供了一套强大且高效的工具和示例,用于处理和流式传输多模态的数据。以下是MediaPipe工具包中提供的相应功能及函数名称。在工具包mediapipe.python中有
·solutions.face_detection:
用于人脸检测。可以检测图像或视频帧中的多人脸,并返回每个检测到的面部的关键点和边界框。
适用于各种应用,包括面部识别、表情分析、访问控制等。
·solutions.face_mesh:
用于高精度人脸网格检测和关键点识别。可以在面部上绘制468个3D关键点,适用于美颜、虚拟试妆等应用。
可以实现精细的人脸特征提取、姿态估计等。
·solutions.face_mesh_connections:
包含面部网格的连接信息,用于连接检测到的面部关键点,从而形成面部网格。
·solutions.hands:
用于手部检测和关键点识别。可以检测手部的21个关键点,用于手势识别和动作分析。
适用于实时手势控制、手势识别应用等。
·solutions.hands_connections:
包含手部关键点的连接信息,用于绘制和连接检测到的手部关键点。
·solutions.holistic:
提供全身的多模态检测,包括人脸关键点、手部关键点和身体姿态。这是一个综合性的解决方案,用于检测和跟踪全身动作。
·solutions.objectron:
提供3D物体检测和跟踪功能,能够检测和估计物体相对于摄像头的3D位置和朝向。实际测试中,支持的模型限于4类物件。
适用于增强现实(AR),虚拟现实(VR),物体识别等应用。
·solutions.pose:
用于人体姿态估计,可以检测33个身体关键点。适用于运动捕捉、健身应用、动作分析等。
能够实时提供人体的骨架信息,有助于姿态校正和健康监测等应用。
·solutions.selfie_segmentation:
涉及如何将检测到的数据呈现出来,就可以用到下面两个函数。
检测到了结果后,我们要进行绘制时可以用这个函数包,提供绘图样式和规格,用于在图像上绘制检测结果。如指定线条和点的颜色、厚度等。
·solutions.drawing_utils:
提供基本的绘图工具,用于在图像或视频帧上绘制检测结果(如关键点、边界框等)。通常与其他检测模块结合使用。
脸部检测(三角填色)
当我们只输出检测到的脸部网格,就是如下图所示的。其中的线条颜色是可调的。如果把这个网格附加到视频的每帧脸部,那么我们就可以看到加了网格的脸。
如果要把组成网格的每个三角形用不同的颜色填充,则需要一点数据的处理。


示例代码中,通过摄像头获取图像,检测到了人脸之后将直接在人脸上加一个多彩面具。网格中的每个三角形的颜色循环填充,这里首先要解决在获取的位置点位中,怎么把临近的三3个点组合起来成为一个不重复的三角形。
import cv2import numpy as npimport mediapipe as mp#初始化Mediapipe的Face Mesh解决方案mp_face_mesh = mp.solutions.face_meshmp_drawing = mp.solutions.drawing_utilsmp_drawing_styles = mp.solutions.drawing_styles#准备随机颜色列表#triangle_colors = [(255, 0, 0), (0, 255, 0), (0, 0, 255)]triangle_colors = [(255, 0, 0), # 红色(0, 255, 0), # 绿色(0, 0, 255), # 蓝色(255, 255, 0), # 黄色(0, 255, 255), # 青色(255, 0, 255), # 洋红色(192, 192, 192),# 银色(128, 128, 128),# 灰色(128, 0, 0), # 栗色(128, 128, 0), # 橄榄色(0, 128, 0), # 墨绿色(128, 0, 128), # 紫色(0, 128, 128), # 蓝绿色(0, 0, 128), # 海军蓝(255, 165, 0), # 橙色(255, 192, 203),# 粉色(75, 0, 130), # 靛蓝(255, 20, 147), # 深粉色(0, 191, 255), # 深天蓝(34, 139, 34) # 森林绿]def generate_random_color():return (np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255))#打开视频捕获设备(假设0为默认摄像头)def main():cap = cv2.VideoCapture(0)if not cap.isOpened():raise IOError("Cannot open webcam")# 获取视频帧的宽度和高度frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))#==========================================# 定义视频编写器,设置输出文件名、编解码器、帧率和帧大小#==========================================fourcc = cv2.VideoWriter_fourcc(*'mp4v')# 创建VideoWriter对象fps = 30.0out = cv2.VideoWriter('Path_to_your_stream_saving_folder/face_mesh_color_triangle3.mp4', fourcc, fps, (frame_width, frame_height))with mp_face_mesh.FaceMesh(max_num_faces=1,refine_landmarks=True,min_detection_confidence=0.5,min_tracking_confidence=0.5) as face_mesh:while cap.isOpened():ret, frame = cap.read()if not ret:break# 将图像从BGR格式转换为RGB格式rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# 处理图像results = face_mesh.process(rgb_frame)# 如果只要显示‘面具’,就创建一个空的黑色图像#blank_image = np.full(frame.shape, (255, 255, 200), dtype=np.uint8) #np.zeros(frame.shape, dtype=np.uint8)# 检测并绘制face meshif results.multi_face_landmarks:for face_landmarks in results.multi_face_landmarks:# 初始化每个点的连接adjacency_list = {i: [] for i in range(len(face_landmarks.landmark))}# 构建连接矩阵for connection in mp_face_mesh.FACEMESH_TESSELATION:start_idx, end_idx = connectionadjacency_list[start_idx].append(end_idx)adjacency_list[end_idx].append(start_idx)# 查找三角形并填充颜色visited = set()#for connection in mp_face_mesh.FACEMESH_TESSELATION:for idx, connection in enumerate(mp_face_mesh.FACEMESH_TESSELATION):start_idx, end_idx = connectionif (start_idx, end_idx) in visited or (end_idx, start_idx) in visited:continuevisited.add((start_idx, end_idx))for adj in adjacency_list[start_idx]:if adj in adjacency_list[end_idx]:idx0, idx1, idx2 = start_idx, end_idx, adj# 获取顶点坐标point0 = face_landmarks.landmark[idx0]point1 = face_landmarks.landmark[idx1]point2 = face_landmarks.landmark[idx2]# 计算像素坐标x0, y0 = int(point0.x * frame.shape[1]), int(point0.y * frame.shape[0])x1, y1 = int(point1.x * frame.shape[1]), int(point1.y * frame.shape[0])x2, y2 = int(point2.x * frame.shape[1]), int(point2.y * frame.shape[0])# 创建一个包含三角形顶点的数组triangle = np.array([[ [x0, y0], [x1, y1], [x2, y2] ]], dtype=np.int32)# 生成随机颜色#color = generate_random_color()# 使用表内的颜色循环填充color = triangle_colors[idx % len(triangle_colors)]# 绘制填充三角形cv2.fillConvexPoly(rgb_frame, triangle, color)break# 再次绘制网格线,区分各个色块视觉mp_drawing.draw_landmarks(image=rgb_frame, #blank_image,landmark_list=face_landmarks,connections=mp_face_mesh.FACEMESH_TESSELATION,landmark_drawing_spec=None,connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style())# 将处理后的帧写入视频文件out.write(rgb_frame)# 显示处理后的图像cv2.imshow('Face Mesh with Random Colors', rgb_frame)if cv2.waitKey(1) & 0xFF == ord('q'):break#释放资源cap.release()out.release()cv2.destroyAllWindows()if __name__=='__main__':main()"""其中函数mp_face_mesh.FaceMesh(max_num_faces=1,refine_landmarks=True,min_detection_confidence=0.5,min_tracking_confidence=0.5)的各个参数:1.max_num_faces:功能:用于指定检测的最大面部数量。默认值:1说明:此参数控制模型在图像中检测多少张面孔。如果您希望检测多张面孔,可以将此值设置为更大。2.refine_landmarks:功能:是否使用跟踪功能来细化面部关键点。默认值:False说明:启用该选项后,模型将提供更精细的面部关键点,特别是在眼睛和嘴巴周围。启用此选项可能会稍微增加计算负担,但会提高关键点的精度。3.min_detection_confidence:功能:用于设置检测的最小置信度阈值。默认值:0.5说明:此参数控制模型在图像中确定面部存在的置信度。如果置信度低于该值,面部将不会被检测到。提高此值可以减少误检,降低可能会增加遗漏的检测。4.min_tracking_confidence:功能:用于设置追踪的最小置信度阈值。默认值:0.5说明:此参数控制在视频流中跟踪面部关键点的置信度。如果置信度低于该值,关键点将不会被追踪。提高此值可以提高追踪的稳定性,但可能会在快速移动或关键点模糊时增加丢失追踪的可能。"""
手部检测(上下左右的手势检测)
如果我们留意现在有很多设备都带有手势控制,那通过下面的演示代码可以大致了解这些手势控制的数据是怎么获取的了。这里使用了solutions.hands 这个功能包处理视频/图像中的手的姿态。
由于工具包中的这个功能可以对应到手指以及每个关节位置坐标,小编用食指的指尖(INDEX_FINGER_TIP)和末关节(INDEX_FINGER_MCP)这两个点的相对位置以及构成的角度来生成上下左右和食指角度的输出。我们先看效果后看代码。
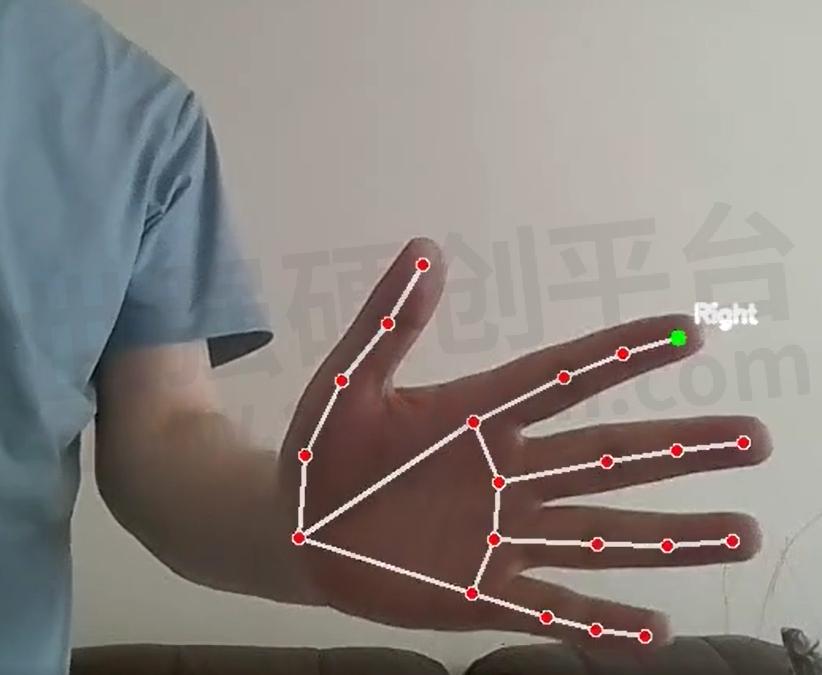
手势识别示例代码如下:
import cv2import mediapipe as mpimport mathimport warnings# Suppress specific warningwarnings.filterwarnings("ignore", category=UserWarning, module='google.protobuf')# 初始化MediaPipe手部模型mp_hands = mp.solutions.handshands = mp_hands.Hands(static_image_mode=False, max_num_hands=1, min_detection_confidence=0.5)mp_drawing = mp.solutions.drawing_utilsdef initialize_camera():"""初始化摄像头。"""cap = cv2.VideoCapture(0) # 打开默认摄像头if not cap.isOpened():raise IOError("Cannot open webcam")return capdef calculate_angle(a, b):"""计算两个点之间的逆时针角度, a为手指尖,b为手掌中心:param a: 手指尖的点 (x, y):param b: 手掌中心的点 (x, y):return: 角度值"""deltaY = -a[1] + b[1] #显示屏的y轴方向和观察角度相反deltaX = a[0] - b[0]if abs(deltaX)< 40 and abs(deltaY)<40:return 'Unknown'angle = math.degrees(math.atan2(deltaY, deltaX))return angle if angle >= 0 else angle + 360def detect_finger_positions(landmarks, frame):"""检测并标记手指指向和数量:param landmarks: 手部关键点:param frame: 视频帧:return: 伸出的手指数和各手指的指向角度"""h, w, _ = frame.shape# 食指指尖index_finger_tip = (int(landmarks[mp_hands.HandLandmark.INDEX_FINGER_TIP].x * w),int(landmarks[mp_hands.HandLandmark.INDEX_FINGER_TIP].y * h))# 食指末关节index_finger_mcp = (int(landmarks[mp_hands.HandLandmark.INDEX_FINGER_MCP].x * w),int(landmarks[mp_hands.HandLandmark.INDEX_FINGER_MCP].y * h))# 获取食指的角度angle = calculate_angle(index_finger_tip, index_finger_mcp)direction = ''if str(angle) == 'Unknown':direction = 'Unknown'else:if angle >= 345 or angle <= 25:direction = "Right"elif angle >= 75 and angle <=105:direction = "Upward"elif angle >= 165 and angle <= 195:direction = "Left"elif angle >= 255 and angle <= 285:direction = "Downward"else:direction = f"{int(angle)}"finger_tips = [4, 8, 12, 16, 20] # 大拇指、食指、中指、无名指和小指指尖的索引# 标识指尖和方向cv2.circle(frame, index_finger_tip, 5, (0, 255, 0), cv2.FILLED)cv2.putText(frame, direction, (index_finger_tip[0] + 10, index_finger_tip[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2, cv2.LINE_AA)return directiondef main():cap = initialize_camera()# 获取视频帧的宽度和高度frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))# 定义视频编写器,设置输出文件名、编解码器、帧率和帧大小out = cv2.VideoWriter('C:/py_TestCode/Py_codes/Hand_recog/output_hand_recog_2.avi', cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), 30, (frame_width, frame_height))while True:ret, frame = cap.read() # 读取摄像头帧if not ret:break# 水平翻转图像,获取镜像图,让图像的读取和观察方向一致mirrored_frame = cv2.flip(frame, 1)# 将BGR图像转换为RGBrgb_frame = cv2.cvtColor(mirrored_frame, cv2.COLOR_BGR2RGB)# 处理图像并检测手部result = hands.process(rgb_frame)# 如果检测到手掌if result.multi_hand_landmarks:for hand_landmarks in result.multi_hand_landmarks:mp_drawing.draw_landmarks(mirrored_frame, hand_landmarks, mp_hands.HAND_CONNECTIONS)direction = detect_finger_positions(hand_landmarks.landmark, mirrored_frame)# 将处理后的帧写入视频文件out.write(mirrored_frame)cv2.imshow('Hand Gesture Recognition', mirrored_frame)if cv2.waitKey(1) & 0xFF == ord('q'): # 按 'q' 键退出breakcap.release()out.release()cv2.destroyAllWindows()if __name__ == '__main__':main()"""留意:hands = mp_hands.Hands(static_image_mode=False, max_num_hands=1, min_detection_confidence=0.5)的配置其中max_num_hands是一次检测手的数量"""
小编尝试并实现过在视频中通过检测手指的相对位置,让程序控制抓拍的功能。大家可以设想一下:如果已经知道了手掌的各个相对位置,如果是你,应该怎么实现这个手势控制抓拍?
人体综合检测
这里我们通过solutions.holistic提供一个把人体的脸部、手部,人体姿态等检测综合起来测试代码。先上效果再附代码。

import cv2import mediapipe as mp# 初始化Mediapipe的Holistic解决方案mp_holistic = mp.solutions.holisticmp_drawing = mp.solutions.drawing_utils# 打开视频捕获设备(假设0为默认摄像头)cap = cv2.VideoCapture(0)# 使用Holisticwith mp_holistic.Holistic(min_detection_confidence=0.5,min_tracking_confidence=0.5) as holistic:while cap.isOpened():ret, frame = cap.read()if not ret:break# 将图像从BGR格式转换为RGB格式rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# 处理图像results = holistic.process(rgb_frame)# 绘制人脸关键点mp_drawing.draw_landmarks(frame, results.face_landmarks, mp_holistic.FACEMESH_CONTOURS,mp_drawing.DrawingSpec(color=(80, 110, 10), thickness=1, circle_radius=1),mp_drawing.DrawingSpec(color=(80, 256, 121), thickness=1, circle_radius=1))# 绘制右手关键点mp_drawing.draw_landmarks(frame, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS,mp_drawing.DrawingSpec(color=(80, 22, 10), thickness=2, circle_radius=4),mp_drawing.DrawingSpec(color=(80, 44, 121), thickness=2, circle_radius=2))# 绘制左手关键点mp_drawing.draw_landmarks(frame, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS,mp_drawing.DrawingSpec(color=(121, 22, 76), thickness=2, circle_radius=4),mp_drawing.DrawingSpec(color=(121, 44, 250), thickness=2, circle_radius=2))# 绘制人体姿态关键点mp_drawing.draw_landmarks(frame, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS,mp_drawing.DrawingSpec(color=(245, 117, 66), thickness=2, circle_radius=4),mp_drawing.DrawingSpec(color=(245, 66, 230), thickness=2, circle_radius=2))# 显示处理后的图像cv2.imshow('Mediapipe Holistic', frame)if cv2.waitKey(1) & 0xFF == ord('q'):break# 释放资源cap.release()cv2.destroyAllWindows()
自拍分割,背景更换
大家对当前很多视频中自拍背景的更换一定不陌生。
solutions.selfie_segmentation通过深度学习模型(例如使用U-Net架构的模型),对预处理后的图像进行前景和背景的预测,并生成分割掩码。对于人体检测,返回掩码的像素都有一个掩码(mask)值,数值范围是0~1.0,越接近1,掩码所在区域是一个人所在位置的置信率越高。
# 创建一个三通道的前景掩码condition = np.stack((segmentation_mask,) * 3, axis=-1) > 0.6"""这行代码将单通道的分割掩码 segmentation_mask 复制为三通道,并维持与源图像相同的形状。np.stack((segmentation_mask,) * 3, axis=-1):将 segmentation_mask 在新的最后一个轴上叠加三次,得到一个三通道的掩码。> 0.1:将其转换为布尔值,表示只选择掩码值大于0.1的区域。"""
演示代码——自拍的前后景分割:
import cv2import mediapipe as mpimport numpy as np# 初始化MediaPipe的Selfie Segmentation模块mp_selfie_segmentation = mp.solutions.selfie_segmentation# 创建Selfie Segmentation对象segmentation = mp_selfie_segmentation.SelfieSegmentation(model_selection=1)# 打开视频捕获设备(假设0为默认摄像头)cap = cv2.VideoCapture(0)image1 = cv2.imread('Path_to_your_background_img/bkgd.jpg')new_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))new_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))bg_image = cv2.resize(image1,(new_width,new_height))# 如果是自建一个背景,就用这个创建一个背景图像(用浅蓝色填充)#bg_image = np.zeros(frame.shape, dtype=np.uint8)#bg_image[:] = (255, 255, 200) # 浅蓝色while cap.isOpened():ret, frame = cap.read()if not ret:break# 将图像从BGR格式转换为RGB格式rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# 使用Selfie Segmentation处理图像results = segmentation.process(rgb_frame)# 获取分割掩码segmentation_mask = results.segmentation_mask# 创建一个三通道的前景掩码condition = np.stack((segmentation_mask,) * 3, axis=-1) > 0.6# 背景和前景分离output_image = np.where(condition, frame, bg_image)# 显示处理后的图像cv2.imshow('Selfie Segmentation', output_image)if cv2.waitKey(1) & 0xFF == ord('q'):break# 释放资源cap.release()cv2.destroyAllWindows()
我们相信,科技赋能之下的未来,将因为每一个微小进步而更加绚丽多彩。传感器作为探测感知的一部分,也将依然是连接各个部分不可或缺的重要一环。在这条充满希望的道路上,安费诺始终与你同行,携手共创无限可能。
- |
- +1 赞 0
- 收藏
- 评论 0
本文由samsara转载自AMPHENOL SENSORS(安费诺传感器学堂),原文标题为:MediaPipe—脸部、手掌及人体姿态特征检测,本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
相关研发服务和供应服务
相关推荐

【经验】解析电动汽车电池组设计和用于泄漏检测需要的传感器类型
车辆靠电力运行,但也会受泄漏的影响。本文安费诺传感器将介绍电动汽车电池组设计和用于泄漏检测的传感器。

【经验】定制的医疗传感器设计中针对应用环境的2个检查清单
在研发一款护理患者并且要求可靠使用的传感器时,传感器的工作环境是与您的传感器制造商讨论的最重要的设计元素之一。最终,设计准确而可靠的医疗传感器归结为:(1)认识到它将面临的各种环境因素;(2)在设备的整个使用寿命内保持精度。

【经验】Melexis传感器EVK75027连接电脑后无图像的处理方法
笔者在实际操作Melexis传感器EVK75027的时候出现Connect正常,但是无任何图像数据显示的情况,前后花费了好多时间。为了方便大家快速处理这类情况,本文将分享处理过程,以供大家使用。

【产品】汽车级单芯片TOF图像传感解决方案MLX75027,集成传感器与信息处理单元,有官方评估套件
MLX75027是Melexis公司 新推出的业界首款汽车级单芯片TOF图像传感解决方案,非常适合应用于手势识别、驾驶员监控、人员或障碍物检测以及交通监控等方面。MLX75027作为一款片上系统SOC,具备了在单片封装中提供VGA分辨率的图像传感以及信息处理功能。解决方案支持640 x 480的像素点,像素点10 x 10 µm,支持850和940 nm的波长,帧率最高可达135 FPS。

安费诺先进传感器的MEMS传感器提供最先进的高性能、高性价比的传感器解决方案
NovaSensor(Amphenol Advanced Sensors的子品牌)的MEMS传感器其准确度、可靠性和尺寸大小而闻名于世,NovaSensor的传感器在医疗、运输和工业等领域的应用中提供最佳性能解决方案。

豪威集团宣布其高性能全局快门图像传感器和处理器适配英伟达Holoscan和Jetson平台
豪威集团,全球排名前列的先进数字成像、模拟、触屏和显示技术等半导体解决方案开发商,当日宣布由OG02B10彩色全局快门(GS)图像传感器和OAX4000 ASIC图像信号处理器(ISP)组成的整体摄像头解决方案现已通过验证,并能够与英伟达Holoscan传感器处理平台及英伟达Jetson™平台配合使用,适用于边缘人工智能(AI)和机器人技术的应用。

【技术】温度对硅阻压力传感器的影响及差分信号放大简要补充分析
本文简单说明硅压阻压力传感器的信号和温补处理对有效信号的影响,以及比较对此类传感器信号处理的方式进行补充,以方便我们使用过程中对于外围信号放大处理部分的正确选用和处理。

有没有氮氧传感器陶瓷芯片?目前本人自研氮氧传感器电控方案已成功,附自研氮氧传感器VS大陆传感器装车测试对比曲线图
世强代理的安费诺旗下SGX品牌的气体传感器,其中MICS-4514可以检测氮氧化合物,请参考:MiCS-4514 a compact MOS sensor Data Sheet【选型】Amphenol Sensors(安费诺)/SGX Sensortech 红外/半导体/电化学/气体传感器传感器选型指南

流量传感器(1)差压式流量传感器
流量传感器是一种用于测量流体在一定时间内通过一定横截面的量(流量)的设备,根据测量原理不同,可以分为但不仅限于以下几种类型: 差压式流量传感器,涡街流量传感器,磁电式流量传感器,超声波流量传感器,质量流量计。本文主要介绍差压式流量传感器。

收购GE先进传感器,拥有12大子品牌,安费诺能为医疗、汽车、工业提供最多样化的传感器选择
拥有12大子品牌的Amphenol Sensors(安费诺)能为医疗、汽车、工业、消费等领域,提供温度、湿度、压力、气体、热验证、位置、振动等多样化传感器选择。

Amphenol Sensors(安费诺)温度传感器/贴片压力传感器/气体传感器产品介绍
描述- 安费诺多品类先进传感器带你感知物联网世界
型号- T6703,SM-UART-04L,NPA-500,NPA-300,NPA-700,SM-PWM-01C,T6713

如何评估一家EV电动汽车的OEM传感器制造商以优化采购?
随着运输业几乎完全转向新车电气化,可靠地采购组件应该是您最不担心的事情。通过仔细评估,传感器技术的第三方组件供应商可以无缝融入您的电动汽车制造流程。在最佳情况下,您的传感器供应商可以增强您的生产,让您可以腾出时间专注于车辆制造的其他方面。

【产品】应用于CCD图像传感器全模拟信号处理的模数转换器,具有25MSPS相关双采样
瑞盟科技MS9943/MS9944是一款应用于CCD图像传感器全模拟信号处理的模数转换器。其内部模块还集成了相关双采样器(CDS)、数字控制的可变增益放大器(VGA)和暗像素钳位电路。MS9943精度是10bit,MS9944精度是12bit。

成熟的OEM传感器制造商可以为电动汽车提供什么?
这是您希望永远不会发生在您的电动汽车(EV)汽车厂的最坏情况之一。 由于一些不可预见的问题,您的生产线已关闭。也许供应商的零件没有及时到达,或者可能是法规发生了变化,使您的车辆组件不合规。或者也许它只是像组件一样简单的事情,个别细微的地方就是无法满足要求。 无论出于何种原因,停线时间都是您的生产设备最不需要的-时间真就是金钱。

传感器在医疗护理中的应用——导管
随着传感器的集成,导管变得越来越复杂,比如可以提供有关患者健康的实时数据,并可辅助提供更准确的诊断和治疗方式。 医疗保健中使用的导管有几种类型,它们结合了传感器技术,每种导管都有其独特的应用和优势。本文介绍四种常见的导管类型,以及导管中用于改善患者护理的传感器。

电子商城
品牌:AMPHENOL SENSORS
品类:Assembly NTC temperature sensor
价格:¥5.0624
现货: 2,000
品牌:AMPHENOL SENSORS
品类:Surface Mount Pressure Sensors
价格:¥97.5000
现货: 51
品牌:AMPHENOL SENSORS
品类:Air Quality Sensors IR LED Dust Sensor
价格:¥40.5000
现货: 35
品牌:AMPHENOL SENSORS
品类:Board Mount Pressure Sensors
价格:¥253.8839
现货: 30
品牌:AMPHENOL SENSORS
品类:Board Mount Pressure Sensors
价格:¥253.8839
现货: 25
品牌:AMPHENOL SENSORS
品类:Board Mount Pressure Sensors
价格:¥227.5314
现货: 25
品牌:AMPHENOL SENSORS
品类:Low Pressure Compact Sensors
价格:¥125.9778
现货: 25
品牌:AMPHENOL SENSORS
品类:Board Mount Pressure Sensors
价格:¥227.5314
现货: 25
现货市场

品牌:SILICON LABS
品类:Switch Hall Effect Magnetic Position Sensor
价格:¥2.2924
现货:126,000

服务
可定制板装式压力传感器支持产品量程从5inch水柱到100 psi气压;数字输出压力传感器压力范围0.5~60inH2O,温度补偿范围-20~85ºС;模拟和数字低压传感器可以直接与微控制器通信,具备多种小型SIP和DIP封装可选择。
提交需求>
可定制温度范围-230℃~1150℃、精度可达±0.1°C;支持NTC传感器、PTC传感器、数字式温度传感器、热电堆温度传感器的额定量程和输出/外形尺寸/工作温度范围等参数定制。
提交需求>
授权代理品牌:集成电路
























































授权代理品牌:分立元件






































授权代理品牌:接插件及结构件













授权代理品牌:部件、组件及配件




























授权代理品牌:电源及模块





授权代理品牌:电子材料














授权代理品牌:仪器仪表及测试配组件




授权代理品牌:电工工具及材料






授权代理品牌:机械电子元件








授权代理品牌:加工与定制












登录 | 立即注册
提交评论