地平线发表自动驾驶的研究成果BAEFormer:基于双向前置交互Transformer的BEV语义分割方法


鸟瞰图(Bird's Eye View,BEV)语义分割是自动驾驶环境感知技术中的一项关键任务。在CVPR2023上,地平线联合中国科学院自动化研究所发表了研究成果BAEFormer:基于双向前置交互Transformer的BEV语义分割方法。不同于现有的后交互和中间交互的方案,BAEFormer提出一个新的通过双向交叉注意力机制进行前置交互的方案,以有效地将多尺度图像特征聚合成更好的BEV特征表示,在保证快速推理的情况下提升BEV语义分割的精度。
背景
近年来,基于纯视觉的感知方法由于其较高的信噪比和较低的成本,在自动驾驶领域占有重要地位。其中,鸟瞰图(BEV)感知已成为主流的方法。在以视觉为中心的自动驾驶任务中,BEV表示学习是指将周围多个摄像头的连续帧作为输入,然后将像平面视角转换为鸟瞰图视角,在得到的鸟瞰图特征上执行诸如三维目标检测、地图视图语义分割和运动预测等感知任务。
BEV感知性能的提高取决于如何快速且精准地获取道路和物体特征表示。图1中展示了现有的两类基于不同交互机制的BEV感知管道:(a)后交互和(b)中间交互。后交互管道[1]在每个相机视角上独立地进行感知,然后将感知结果在时间和空间上融合到一个统一的BEV特征空间中。中间交互管道[2,3,4]是最近使用得最广泛的方案,它将所有的相机视角图像耦合输入到网络中,通过网络将它们转换到BEV空间,然后直接输出结果。中间交互管道中的特征提取、空间转换和BEV空间的学习都有一个明确的顺序。
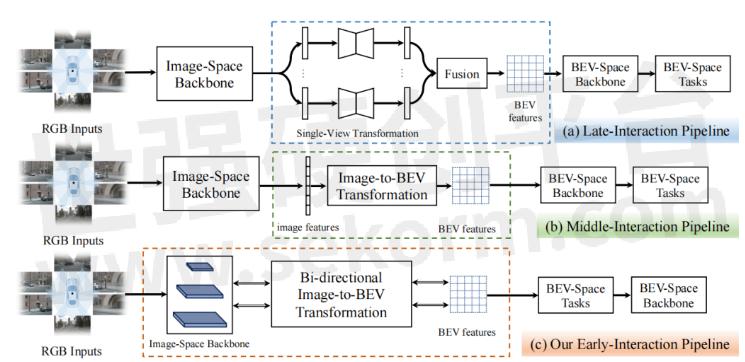
图1:后交互、中间交互和我们提出的前置交互框架示意图
基于视觉的BEV感知的核心挑战是从仿射视角(Perspective View, PV)向鸟瞰图视角(BEV)的转换。然而,利用现有的两种交互策略将PV转换到BEV仍然存在许多问题:(1) 图像空间backbone只依次提取不同分辨率的图像特征,而没有融合任何跨分辨率的信息;(2) 现有的交互策略中核心模块的计算量主要由图像空间backbone占据,但它不包含任何BEV空间信息,导致大量的计算并没有执行PV到BEV转换这一关键任务;(3) 后交互策略和中间交互策略的前向处理中的信息流是单向的,信息从图像空间流到BEV空间,而BEV空间中的信息并没有有效地影响图像空间中的特征。为了解决这些问题,我们提出了一种新的基于Transformer的双向前置交互框架,以有效地将多尺度图像特征聚合成更好的BEV特征表示,并执行BEV语义分割任务。
与现有的两种策略相比,我们提出的前置交互方法具有明显的优势。首先,我们提出的双向前置交互方法可以融合全局上下文信息和局部细节,从而能够向BEV空间传递更丰富的语义信息。其次,我们提出PV到BEV的转换不仅可以是图像特征提取后,而且可以在提取过程中进行逐步转换,于是,通过我们提出的双向交叉注意力机制,信息流可以隐式地进行双向交互,从而对齐PV和BEV中的特征。此外,我们的方法可以将跨空间对齐学习扩散到整个框架中,即图像网络学习不仅可以学习到良好的特征表示,而且可以起到跨空间对齐的作用。
方法
整体框架
BAEFormer的整体框架如图2所示,总共包含两个部分:(1)双向前置交互编码器,用于提取图像特征并将其从PV转换为BEV;(2)将低分辨率BEV特征上采样到高分辨率BEV特征的解码器,用于执行下游任务。
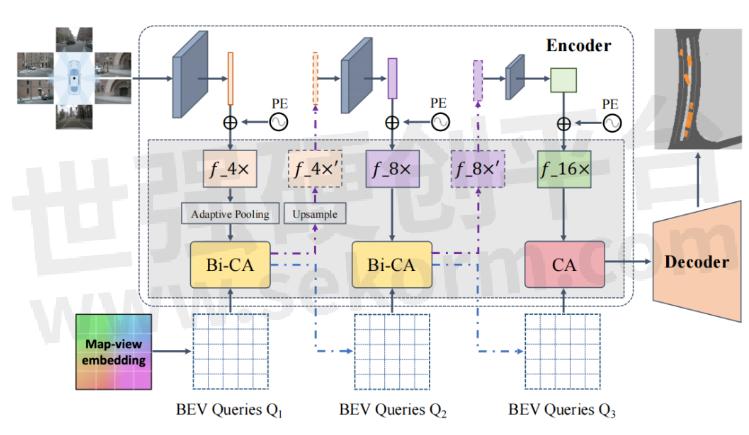
图2:BAEFormer整体框架图
前置交互
对于前置交互模块,我们使用EfficientNet[5]的预训练模型来提取环视图像的特征,特征提取器包含三层,分别提取图像的4x,8x,16x分辨率的特征。4x分辨率的特征首先被提取出来,通过一个降采样模块之后和BEV特征进行交互得到更新之后的4x分辨率特征,将更新之后的4x特征上采样,并作为特征提取器的下一层的输入来提取8x分辨率特征。以此类推,我们得到更新之后的8x特征并作为特征提取器最后一层的输入,由此得到16x图像特征。我们的多尺度前置交互方法可以充分利用分层预训练的模型来整合多尺度图像特征。同时,BEV的空间信息可以流入主干网络,使前置交互主干网络承担了部分异质空间对齐的功能。
双向交叉注意力
如图3中所示,我们提出的双向交叉注意力模型包含两个分支,一个用于多视图图像特征的精细化,另一个用于BEV特征的精细化。
首先,N个环视图像特征首先被编码为查询特征,键特征和值特征,其中c表示特征维度,h和w分别表示特征的高和宽。相似的,BEV特征编码也被转换为查询特征,键特征和值特征。于是图像特征和BEV特征的交叉注意力可以表示为:

整个Transformer模块就可以使用下式计算:
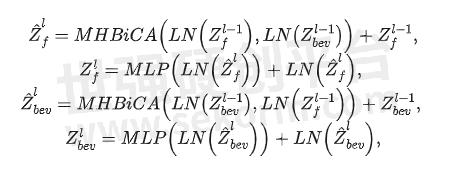
其中,![]() 和
和![]() 表示第l层的输入,
表示第l层的输入,![]() 和
和![]() 表示第l层的输出。LN(∙)表示层归一化操作,MLP(∙)表示有2个全连接层和一个非线性层的多层感知机模块,MHBiCA(∙)表示拥有多头交叉注意力机制的BiCA(∙)模块。
表示第l层的输出。LN(∙)表示层归一化操作,MLP(∙)表示有2个全连接层和一个非线性层的多层感知机模块,MHBiCA(∙)表示拥有多头交叉注意力机制的BiCA(∙)模块。

图3:双向交叉注意力框架图
实验结果
表1展示了BAEFormer方法和之前的方法在两种设置下的性能、参数和推理速度的对比结果。可以看出,BAEFormer在使用相同输入分辨率(224x480)的设置下,在精度上超过了现有的实时方法。同时,虽然先前的BEVFormer[2]实现了高性能,但它非常耗时,模型参数高达68.1M。我们的BAEFormer在大输入图像分辨率(504x1056)下的运行速度比BEVFormer快12倍,而参数量大约是它的1/12。
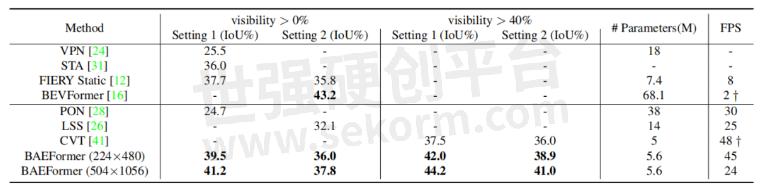
表1:nuScenes数据集上车辆类别的语义分割结果
消融实验表2展示了我们在nuScenes数据集上对车辆类别进行的不同交互方式的消融实验。实验结果表明,我们的BAEFormer方法可以将双向交叉注意力机制和前置交互方式充分地结合以得到更好的BEV特征表示。
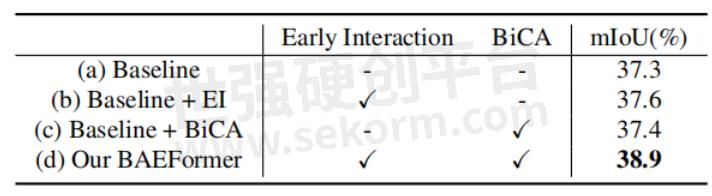
表2:不同交互方式的消融实验
表3展示了具有不同输入分辨率和图像特征尺度的模型的mIoU性能和内存使用情况。结果说明,使用多尺度特征可以带来更好的性能;增大输入图像分辨率可以提高性能,但会带来显存的剧增;我们发现,如(j)-(n)所示,在交互过程中,输入图像的分辨率对最终的精度没有太大的影响;因此我们可以在提高输入图像分辨率来提升性能的同时,通过对交互时的图像特征进行降采样来保证计算量是可控的。
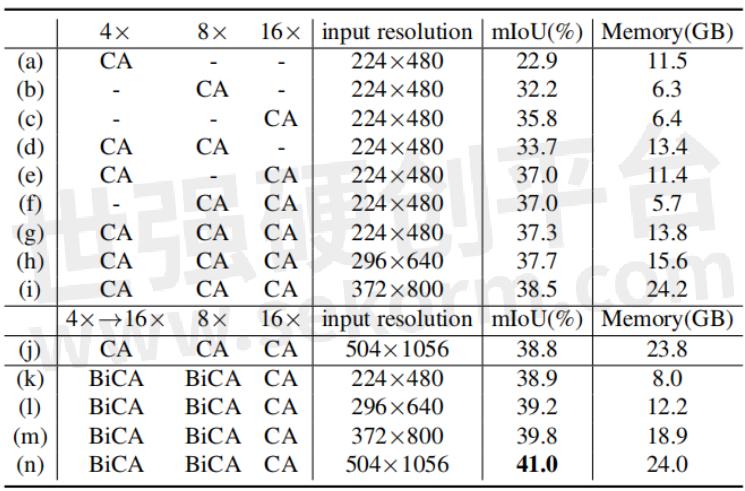
表3: 不同输入分辨率和不同图像特征尺度的组合
可视化结果
图4展示了BEV下的可视化结果,可以看出BAEFormer对比baseline模型,不仅对于近处物体漏检(红色圈)的数目有效减少,且对于远处物体(绿色圈)也能进行有效的感知,进一步说明了我们方法的感知能力具有一定的优势。
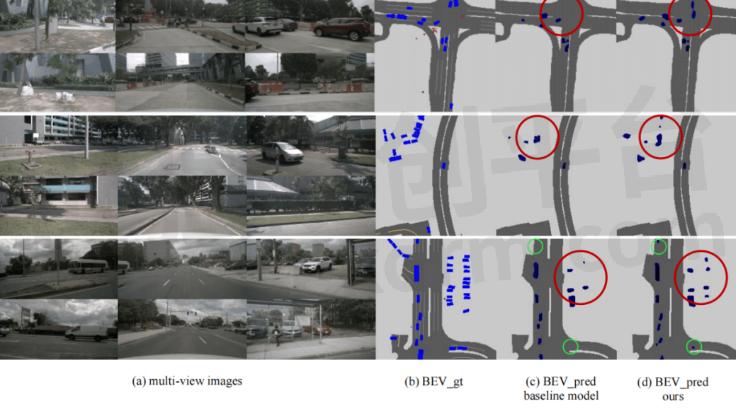
图4:不同模型的可视化结果对比
结论
在本文中,我们提出了一种称为BAEFormer的BEV语义分割新框架,采用双向交叉注意力机制,通过对图像特征空间和 BEV 特征空间中的信息流施加双向约束来建立改进的跨空间对齐,同时利用前置交互方法来合并跨尺度信息,并实现更精细的语义表示。实验结果表明,BAEFormer在保持实时推理速度的同时能够提高BEV语义分割的性能。
参考文献:
[1] Bowen Pan, Jiankai Sun, Ho Yin Tiga Leung, Alex Andonian, and Bolei Zhou. Cross-view semantic segmentation for sensing surroundings. IEEE Robotics and Automation Letters(RAL), 5(3):4867-4873, 2020.
[2] Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. arXiv preprint arXiv:2203.17270, 2022.
[3] Yingfei Liu, Tiancai Wang, Xiangyu Zhang, and Jian Sun. Petr: Position embedding transformation for multi-view 3d object detection. arXiv preprint arXiv:2203.05625, 2022.
[4] Brady Zhou and Philipp Kr¨ahenb¨uhl. Cross-view transformers for real-time map-view semantic segmentation. In CVPR, pages 13760–13769, 2022.
[5] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In ICML, pages 6105–6114. PMLR, 2019.
- |
- +1 赞 0
- 收藏
- 评论 0
本文由ll转载自地平线HorizonRobotics公众号,原文标题为:CVPR 2023|BAEFormer:基于双向前置交互Transformer的BEV语义分割方法,本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
相关推荐

地平线算法工具链新进展! GANet在征程®5上实现高效部署
地平线征程5是专为高阶智能驾驶打造的智能计算方案,搭载地平线第三代架构BPU--贝叶斯(Bayes),算力可达128TOPS,是率先实现前装量产的国产百TOPS级智能计算方案。基于征程5开发的高等级自动驾驶方案可实现ADAS功能、高速导航智能驾驶、城区导航智能驾驶和智慧泊车的全场景覆盖。

地平线征程家族出货量突破700万,刷新百万量产速度!
近日,地平线征程家族出货量正式突破700万套,在刷新百万量产速度的同时,也标志着地平线软硬结合的高级辅助驾驶与高阶智驾解决方案实现大规模量产落地!

一组数字读懂地平线高阶智驾技术开放日!
地平线在北京举办的高阶智驾技术开放日上,展示了其Horizon SuperDrive™(HSD™)系统的最新进展。该系统旨在2025年实现高阶智驾的规模化发展,提供全场景智驾模式和安全保障。地平线的技术在多个算法挑战赛中获奖,并计划通过World Model和交互博弈模型实现性能和体验的优化。征程6芯片将支持这一全场景智驾解决方案,以实现高效、拟人化的驾驶体验。


【经验】地平线ISP工具Control tool的使用方法介绍
Control tool是isp-tuning时tuning ISP参数的图形界面工具,对于刚接触地平线的开发者来说,会比较陌生,下面详细介绍Control tool的使用方法。

地平线旭日® X5 介绍
描述- 地平线公司作为智能驾驶计算方案提供商,专注于深度神经网络芯片研发。其产品征程系列和旭日系列芯片广泛应用于自动驾驶、智能驾驶辅助系统等领域。公司拥有150+车型前装定点,1000万+出货量,200+生态合作伙伴,1200+专利,1500+研发人员。地平线旭日芯片持续迭代,提供高效进化的智能平台,支持多种算法加速需求。旭日5芯片集成了CPU、BPU、GPU、DSP四合一异构加速,满足不同算法加速需求。

【经验】地平线X3M SDB开发板烧录ubuntu镜像实操和注意事项
地平线X3M SDB开发板,地平线论坛已经支持yocto linux和ubuntu两种SDK包,本文实操烧录ubuntu镜像以及说明注意事项。

地平线X3M核心板规格说明书
描述- 地平线X3M核心板(X3M SOM)是一款基于X3M芯片设计的AI处理模块,具备图像检测、分类、分割等功能。该模块适用于AI摄像头、机器人、边缘计算盒子等多种场景,旨在帮助客户加速产品研发进程。
型号- X3M,X3M SOM

【经验】地平线DDR压测工具stressapptest的使用方法
stressapptest是开源工具,可以进行内存、CPU和存储的压力测试。本文主要介绍地平线DDR压测工具stressapptest的使用方法。

世界模型:地平线眼中的「认知大脑」
在8月28日举办的地平线高阶智驾技术开放日上,地平线创始人兼CEO余凯博士就当下火热的端到端,智能驾驶未来发展趋势、地平线软硬结合的王炸产品Horion SuperDrive™(HSD™),与参会嘉宾进行了真诚的分享。其中,余凯博士提到,“端到端是每家公司都能掌握的,魔鬼在细节中。” 本篇文章即从端到端讲起 ,并为大家剖析何为地平线的“驾驶世界观”。

【经验】地平线Soc X3M适配新的sensor时MIPI CSI、VIO配置注意事项
地平线X3M适配新的sensor,除了要实现sensor寄存器的初始化,以及代码库实现,还需要做X3M端的MIPI CSI配置,以及VIO的配置,本文将介绍地平线Soc X3M的MIPI CSI、VIO配置注意事项。

【经验】地平线X3M开发板添加dummy_codec虚拟声卡驱动的方法
一个完整的声卡信息由cpu_dai,codec_dai,platform,dai_link组成。本文将详细介绍地平线X3M开发板添加dummy_codec虚拟声卡驱动的方法。

【经验】地平线X3M芯片通过软件调节降低功耗的三种方法
地平线X3M SoC芯片包含4个53核,主频1.2Ghz,还有2个BPU核,主频1GHz,算力最高5Tops,在处理负责图像逻辑的情况下,需要对功耗进行必要的控制,保证芯片能正常工作。下面是三种通过软件调节降低芯片功耗的三种方法。

【经验】地平线X3M SoC芯片烧录efuse的方法
地平线X3M SoC的efuse的主要目的是自动识别不同厂商的DDR以及DDR类型。现在的DDR频率默认是3200,有些DDR的最高频率为2666,不烧写efuse,频率变为3200会影响启动。

智驾征程|地平线征程®3智驾科技赋能,哪吒S猎装正式上市
作为哪吒汽车的战略合作伙伴,地平线提供领先智驾方案,基于征程®3赋能哪吒S猎装为更多“哪铁”用户带来安全、舒适、美好的智能出行体验,助力哪吒汽车坚定实现“科技平权”的初心。

电子商城

现货市场
授权代理品牌:集成电路
























































授权代理品牌:分立元件






































授权代理品牌:接插件及结构件













授权代理品牌:部件、组件及配件




























授权代理品牌:电源及模块





授权代理品牌:电子材料














授权代理品牌:仪器仪表及测试配组件




授权代理品牌:电工工具及材料






授权代理品牌:机械电子元件








授权代理品牌:加工与定制












登录 | 立即注册
提交评论