地平线高级研发总监分析如何打造一颗“好用”的自动驾驶AI芯片


地平线推出的“地平线AI芯片技术专场”第二期课程中,高级研发总监凌坤就《好的自动驾驶AI芯片更是“好用”的芯片》这一主题进行了讲解。凌坤老师从软件2.0的开发范式讲起,结合地平线自动驾驶AI芯片的开发实践,从软硬结合+软硬解耦的平衡、AI芯片开发原则、软件2.0开发范式的基础设施艾迪AI开发平台、天工开物工具链、丰富的软件栈等方面深入讲解如何打造一颗“好用”的自动驾驶AI芯片。

本文主要分为以下3个部分:
1、关注软硬结合前提下的软硬解耦
2、好用的关键:提升产品研发效率
3、用软件2.0基础设施、工具链、开放软件栈和丰富样例成就开发者
过去很多年里,我们一直在做传统意义上的算法和软件研发。在这套体系下,程序员首先要理解清楚问题是什么?怎么解?在此基础上写好代码,并让代码运行起来,看是否正确。而随着芯片性能越来越高,存储数据、模型容量越来越大,机器学习方法帮助我们解决了许多实际的问题,因此进入到软件2.0时代。伴随着未来摩尔定律的持续演进,基于软件2.0的研发工作会越来越多,我们要准备好迎接软件2.0的开发时代。
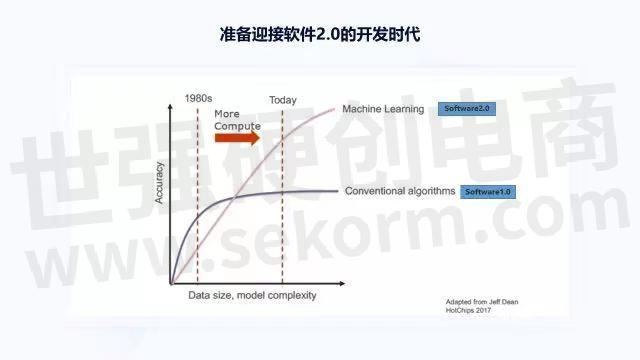
回看软件2.0的开发范式,它与软件1.0完全不同。在软件1.0中,当我们要解决一个问题时,首先需要开发者把问题定义的十分清楚;然后把问题分解成具体步骤,并把每一步的解决方法也想的非常明白;再写出代码,代码做好测试后集成起来,看能否解决实际问题。如果不能解决,反过来再看,是问题没有定义清楚?问题没有分解清楚?问题的解决方法不正确?还是程序员代码没写好?反复检查、调试、验证,以上就是软件1.0开发的闭环迭代过程。例如当控制一辆车往前走时,如果路上没有超过限速,前方没有障碍物,那接下来车辆可以加速,加速到多少时不能再加速,这是一个典型的 if-then-else问题,所以整个软件1.0时代的代码程序都是围绕 if-then-else、 for循环函数等典型的概念展开。
当到了软件2.0时代,面临的是一个完全不同的开发模式。首先需要定义问题,同时需要大量的数据,数据用来表示几种不同的情况;然后再设计一个适当的模型,模型能够对问题做分类或检测;之后在大量标注数据上做模型训练,训练完成后再部署集成, 在场景中看大概有多少结果是正确的,多少结果是错误的;再持续的采集数据,做标注、训练,或者更改模型的设计,来解决这些错误的badcase。
在过程中,没有一个程序员能把问题解法想得十分清楚。比如识别一只猫,猫的毛发是弯的还是直的、猫的颜色是花的还是纯色,猫的两只耳朵是竖着的还是弯着的,程序员并不是通过这种方式解决问题。从每一个像素点定义的角度来看,这些问题是一个数据驱动的问题,即通过100万张或1000万张不同的图片给模型做训练。在这种模式下,程序员不需要对问题应该怎么解有非常深刻的认识,也不需要知道计算机每一步该怎么操作,只需关注卷积神经网络的容量和里面的信息,反向传播时梯度是怎样传播的,激活函数应该怎么设置等问题。
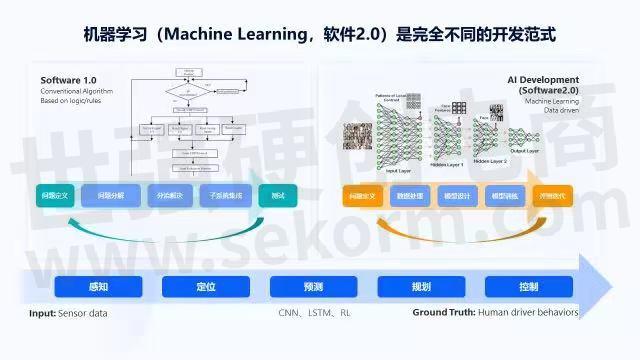
软件2.0时代的方法可以让机器像人一样看懂和听懂周围的世界,所以它有广泛的应用场景,而且随着摩尔定律的持续进步,有非常大的成长空间。关于自动驾驶芯片的好用,也应该围绕着软件2.0的开发范式展开,因为1.0时代已经有四五十年的积累,各种工具已经非常完善,在此基础上更多的是一些微创新,而2.0时代则是一种底层方法论层面的颠覆式创新。
在这套开发范式下,对于机器来说,软件2.0的技术可以让它感知周围的世界,知道自己在世界里处于什么位置,当世界里有很多自主移动的目标时,可以预测周围的目标的运动轨迹,可以规划自身的动作是绕开目标,还是直着前进或停下来,进而控制自己完成动作。
01 关注软硬结合前提下的软硬解耦
首先回顾下历史,在看历史时会发现一个很重要的点是“应用对性能的追求没有止境”。在这种情况下,很多芯片一代一代的往前走。从1970年开始,各种各样的芯片、计算设备层出不穷,也造就了很多PC时代。
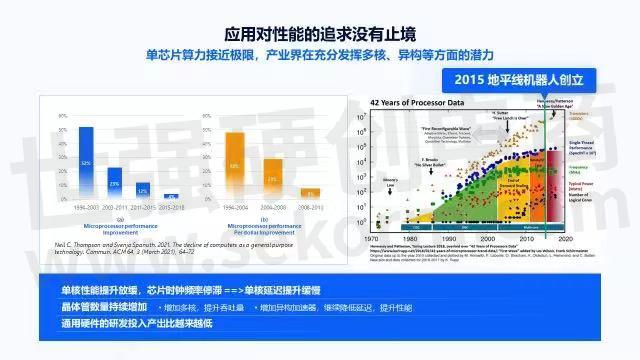
上图左边的蓝色统计表来自于2021年ACM通讯的一个统计结果,该图表明在过去的20多年里,微处理器性能的提升在逐渐放缓。同时站在供应商的角度,从黄色统计表中可以看出,单位研发投入下微处理器的性能提升也在逐渐变小,所以未来在通用处理器上的研发投入产出比会越来越低。越来越多的公司会把更多精力投在多核和异构加速器上,右图就是一个很好的证明。
由于人们对性能的追求没有止境,单个芯片上的晶体管数量会呈指数级增长。而单个线程的性能,在2010年左右逐渐放缓。因为物理条件的限制,频率也不再增长,并随着工艺制成的变化,整个芯片的功耗也处于一个停滞的状况。与此同时,单个芯片里的逻辑处理器核心变得很多,这会导致我们在追求非常高延迟增强时,由于单线程的性能没有大的变化,使得我们无法通过单线程的通用处理器达到很好的效果,只能把代码做并行,或引入异构加速器来实现性能优化。

虽然单个线程的性能处于增长缓慢甚至停滞的状态,但在软件和算法层面,还有非常多的空间可以做优化。上图上半部分是对矩阵乘例子的优化。当我们用Python实现矩阵乘时,假设它的速度为1,把 Python代码改成Java或C时,可以看到有11倍甚至47倍的提升。这是语言之间的变化,只是用不同的编程语言改写,与芯片架构无关。之后的循环并行利用到芯片上的多核;并行分置则是把矩阵分块,然后放在缓存里;再用自动向量化,自动化的利用芯片里已经提供的数据流并行CMD指令;当使用较宽的AVX向量时,在代码里面直接写AVX函数调用,最多可以得到6万多的加速比。所以,当我们围绕软件和算法的特点挖掘更多硬件特性时,就能通过这种软硬结合的方式获得非常大的性能提升和极具性价比的计算平台。
最近,有件有意思的新闻,Intel在新的大小核架构中,为了保证软件兼容性,放弃了部分芯片中AVX512支持。
接下来看下软硬结合和软硬解耦过去在整个技术栈中是怎样做的?当我们看标准的C和C++代码时,这与芯片无关,可以实现软硬解耦,它是怎么做到的呢?我们以LLVM编译器为例,编译器里有前端、中端和后端,其中前端和中端里有很多的代码分析、优化和变换,这些都与芯片架构无关。编译器后端也有与芯片有关的部分,像ARM后端和RISC-V后端,通过这些之后,编译器可以把代码变成可执行文件,这些可执行文件可以部署在ARM芯片或RISC-V芯片上运行。
对比Intel AVX禁用的消息, 在最新的ARM处理器架构上,引入了一个SVE向量处理单元,它可以用来取代NEON。NEON是在 ARM架构上的一个SIMD扩展指令集,它类似于AVX的单指令多数据,但NEON是定宽的,即128比特。SVE则是变长的,它可以实现128比特、256比特和512比特的宽度。在性能评估上,最高可以获得3.5倍的加速比。在SVE指令集层面并没有详细规定{128、256、512},它是在具体芯片实现时,硬件可以自己定一些常数来做,而所有的指令都是通过自己判断或者加入一些参数的方式进行,可以不考虑向量的实际宽度,即在相同的指令下,既可以在128比特宽度下执行二进制代码,也可以在256比特或512比特宽度下执行二进制代码,不会出现英特尔AVX512的情况。所以ARM在数据并行方面,在二进制代码兼容性的思考是比较超前的,它在想办法规避掉问题,保持二进制兼容,通过这种方式能很好的支持底层晶体管为上面的服务,同时保持好软硬解耦。
刚刚讲到了C和C++,在真正面向AI时代时,不得不提到GPU,即CUDA。利用GPU里大量并行的单指令多线程架构,可以实现非常复杂的数据流并行运算,进而加速上层的张量计算,来获得比较好的 AI性能加速。
这里很典型的CUDA是英伟达提出来的,它通过NVCC编译器变成PDX代码,PDX代码在各代GPU上都会有自己的PTXToGPU编译器,再通过驱动就可以在Ampere架构GPU或Turing架构GPU上运行。在过去的很多年里,英伟达在这方面有非常多的积累,而且形成了比较强的市场主导地位。
在AI时代,英伟达基本上是在唱主角的,虽然AMD最近市值有了比较大的提升,但AMD对AI方面的知识一直处于被动的状态。最近AMD比较大的动作是提出了ROCm编译器,虽然没有明确的介绍,但可以认为它是为了更好的兼容CUDA生态,所以它会把CUDA代码先通过一个转换器转成HIP代码,再通过ROCm编译器,最后在AMD的GPU上运行。
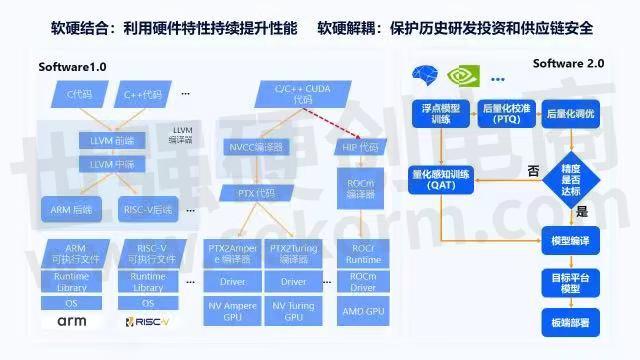
上图右部分画了虚线,这是由于当我们决策是买英伟达GPU,还是买AMD GPU做AI计算加速时,大部分的开发者都会去选择英伟达,因为不用担心编译器或Runtime的问题,或者有些bug没有被测到,进而导致生产效率受到很大影响,所以右边用了虚线。这条线虽然存在,但是好与坏,很多的用户和开发者都已经用脚在投票,这是一个典型的软硬结合和软硬解耦不易做到权衡的问题。而且在英伟达的历代GPU上可以通过PTX代码实现比较好的软硬解耦。同时,软硬结合就体现在了NVCC编译器和CUDA对芯片架构的深层次挖掘和利用上,上面是软件1.0。
再来看软件2.0,它的整个开发流程大概分成以下几个阶段:先对一个模型进行训练,之后做量化,因为量化能带来芯片功能和效能的提升,再来看精度是否达标,然后做模型编译到芯片平台上运行。上述这些步骤,包括地平线在内,大部分芯片厂商都可以做到比较好的软硬解耦。通过这种形式的软硬解耦能够保证开发者过去写的一些历史研发代码可以在平台上更好的运行,同时也能保证一定的供应链安全。
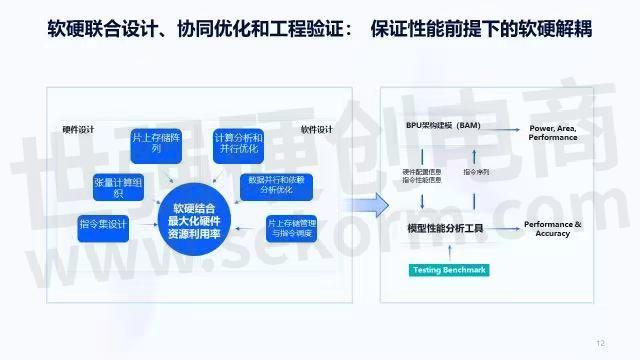
刚刚在回顾历史,而面向 AI计算的软硬件设计还需要一个比较完整的工程架构来保证。首先要有性能,在此基础上,再来看怎么样做好软硬件解耦。结合地平线的实践,一般情况下会从硬件设计和软件设计两个层面来看,硬件设计主要针对存储、张量计算组织、指令集设计,软件方面包括计算分析和并行优化、数据并行和依赖分析优化、片上存储管理和指令调度。它们的核心目标是为了能够最大化硬件资源的利用率。
为了保证未来持续的竞争力,需要更多的晶体管来做更多的事情,但是这些晶体管到底用来做什么?怎么样保证最大化利用好这些资源,为上层AI算法和应用提供足够多的AI计算能力,就需要软硬结合的一整套工程迭代框架。
地平线有一个BPU架构建模工具,它可以对功耗、性能、面积做建模,输入的是指令序列,建模工具为模型性能分析工具提供了一些硬件配置信息和指令性能信息。模型性能分析工具则提供了性能和精度方面的分析结果,同时为BPU架构建模提供输入。BPU架构是在探索未来的芯片架构,模型性能分析工具则在探索接下来的编译器、模型量化工具、训练工具应该怎么做。它们有个很重要的输入:Testing Benchmark。如果Testing Benchmark没选好,整个闭环会转歪,所以 Testing Benchmark选取十分重要。
Testing Benchmark的选取一定要把握好算法演进趋势,由于Benchmark里面包含了丰富的、代表未来演进趋势的算法模型,利用好Benchmark和相关变换之后,就能更好的平衡软硬结合和软硬解耦。像地平线已经达到百万芯片出货量的征程二代和征程三代芯片里就有比较多的设计,在2016年、2017年时已经考虑到了相关一些算法的演进趋势。
地平线就有一个非常强大的算法软件团队,这个团队不停的去看、去听或去实践算法的实际应用情况,及未来的演进趋势,更好的为Testing Benchmark提供输入。
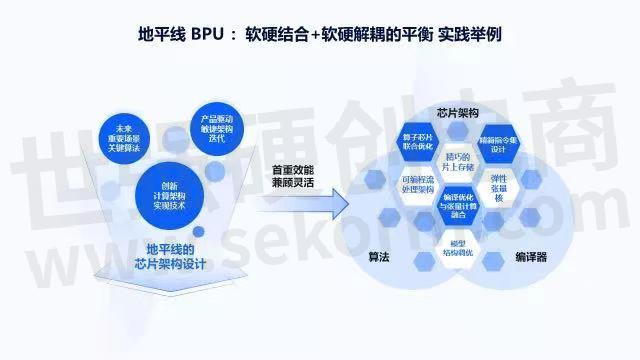
接下来将结合地平线的实际情况进行说明,希望可以给大家一些新的启发,或带来一些不同的观点和角度。在地平线的芯片架构设计中,包括Testing Benchmark的选取,面向的都是未来重要场景里的关键算法,而且一定要在产品驱动里做架构迭代,要看产品里模型的泛化性怎样,模型实际应用起来运行的如何,它对哪些目标能够识别的很好,哪些还有问题,把这些点在产品层面尽量挖掘出来,然后在产品驱动敏捷架构迭代和未来重要场景关键算法两个层面的结合下形成Testing Benchmark。
同时,地平线有很多世界领先的专家团队,他们结合过去几十年在计算架构、软件、硬件、芯片和算法方面的积累,预判在AI计算层面还有哪些工作可以做相关的优化和创新。这里首先看重效能,并要兼顾灵活,具体会从芯片架构、算法和编译器三个角度来做,而且这三个方面会有很多交叉领域的思维碰撞及工程实践迭代。例如当我们看指令集时,不仅仅是看RISC-V指令集,而是看在编译器眼中张量计算到底是什么。在这种情况下,我们应该怎么样做指令集,弹性张量核、片上存储、可编程流处理架构等这方面有哪些思维碰撞,通过这些方面的具体的技术点来给大家一个大概的感觉,即软硬结合和软硬解耦在什么样情况下可以找到平衡。
当我们提到软硬结合和软硬解耦时,最终芯片都需要最大化的解放开发者的生产力,让他们快速研发产品。所以地平线坚持做好自动化工具,自动化的利用芯片特性,如果芯片特性不能被自动化利用,那究竟是工具的问题,还是芯片架构设计的问题,抑或是算法层面上的问题,这些都需要严格的论证。在这个情况下,我们把工具做好,自动化的利用这些特性,自动的分析模型,分析依赖,去变换、提高性能,并降低带宽。
在编译器优化上,首先是把张量计算拆分开,通过对特征图和卷积kernel的计算拆分,编译器可以用更小的粒度描述计算,避免引入不必要的依赖,提升数据并行性,创造潜在的调度机会。
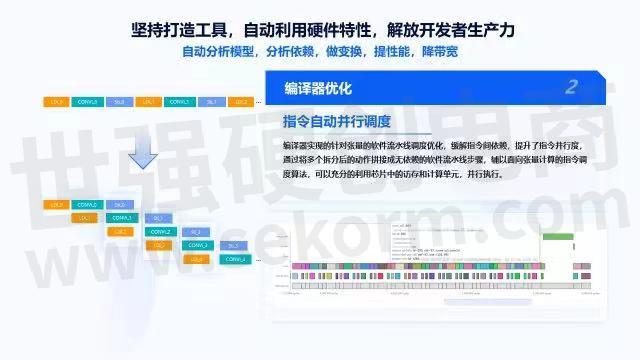
接着是指令调度,指定调度也是非常经典的编译器优化方法,我们在编译器层面也做了很多工作。首先它是张量,相对于寄存器来说,很大的不同在于张量是变化的,它有不同的channel、kernel,卷积核。因此,需要对张量数据做建模,同时在软件方面要有很强的指令流水线调度,即是软流水。
软流水的流程如左上角图所示,做完Load、Conv、Store后,再做Load、Conv、Store。由于两个Load之间没有必然的联系,可以用如左下角图的方式做成流水线,可以看到每一组的方块本身就是一个循环体,但是循环体内部的三条指令没有必然的联系,通过这种方式三个指令就能自由灵活的同时运行。右下角图表示一个实际的网络执行过程,可以看到卷积阵列基本上是完全排满的,没有任何缝隙。ddr_load在中间配合着为卷积阵列提供输入,同时会有一些别的运算。整体上可以获得非常高的卷积利用率。
上面是提到了卷积切分和指令调度,但很关键的问题是这么多层该怎么样切分?这首先想到了C语言编译器是怎么做的,它针对每一个函数内部做分析、编译,然后看函数内部的这些代码该怎样做相互之间的优化。同理,当把卷积神经网络的一次Inference看成一个函数时,应该通盘去看函数内部的整个执行过程中计算要怎样去做。
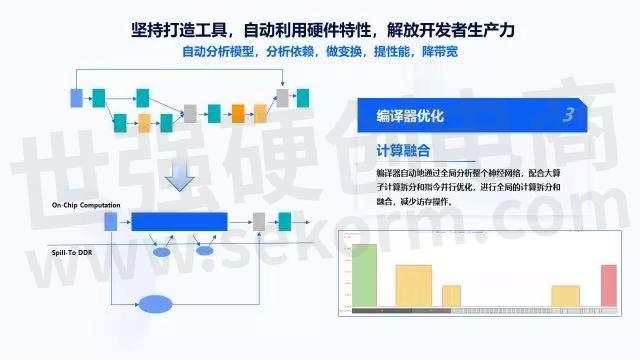
在地平线的实践中,我们利用了一套计算融合技术,把算子综合去看。如上图左边所示,把operator整个融合在一起,因为片上的memory总是很有限的,而且很贵,必要时溢出一些数据到DDR里,腾出一块片上空间来保证执行可以进行下去,这块空间越小越好,这样整个DDR的访存带宽可以很小。
右下角这张图是720p图片输入到ResNet101网络中,可以看到开始是先把图片装载到芯片内部,然后通过中间的运算,再把它存到DDR里。中间的过程只有三次DDR的访问,这三次实现了一些数据的搬进、搬出,前面大概是一个18层的层融合输出,再有一个14层的层融合输出,最后是一个三层的融合输出,通过这种方式可以最小化整个Inference过程中对DDR带宽的访存压力。与此同时,还可以看片上的memory到底被利用的怎样,挖掘接下来memory怎样被利用满,是在编译器上优化,还是在芯片架构或算法张量大小上做更合理的调整。

上图是把所有的效果放在一起宏观展示,可以看到有全局的计算融合,单层计算拆分和全局计算融合和依赖分析与指令调度。
02 好用的关键:提升产品研发效率
什么是“好用”?我认为好用是把开发者头脑里对产品的思考,利用芯片上所能提供的辅助设施,以最快的方式打造出他最想要的产品,来提升研发效率。

怎么样提升研发效率,也不是一个容易衡量的词,所以先看历史。上图是过去100年时间里整个计算技术的发展,从最早利用机械摇杆的密码破译、线缆插拔的弹道计算,到商用计算、办公游戏云服务,再到大家比较熟悉的移动通信,包括安卓和iOS。在此之前都无法绕开图灵机以及控制图灵机的编程模型,去实现人们想要机器做的行为。
如果大家摸索过几种不同的编程语言时,可以看到不管是C、C++、Java或Python,它的核心还是if-else、循环、跳转,只不过在用途、编译计算等方面会有一些不同,但基础东西是没有变的。但是到了自主机器人时代是完全不同的,机器可以看懂和听懂周围的世界,这是一个数据驱动的可微分编程方式。在贯穿在整个过程中,应用场景和开发范式都在持续迭代。
再回过头来看,2.0时代越来越重要,所以围绕着2.0时代的“好用”,就是2.0时代的开发。但会遇到一个问题,到底应该做什么样的事情,以什么样的标准来衡量,才能把软件2.0时代的开发做得好。我请教了一个老师:C++之父,他在2020年发表了一篇paper,这篇paper在讲2006年到2020年14年间C++的发展。
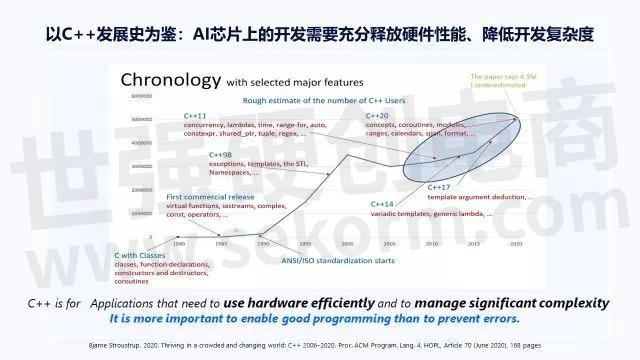
上图的纵坐标是C++社区的活跃程度,横坐标是时间,可以看到C++在一个很快速的上升期之后,在2000年左右出现了下降,在2006年出现了一个拐点,之后推出了C++11,C++14,C++ 17 ,C++20,软件开发者的数量开始有了非常大的提升。
在这14年里,Bjarne带领整个C++标准委员会讨论究竟需要把什么样的内容放到C++标准里,让全世界的C++开发工程师利用他们手上能拿到的编译器做好开发,比如C++11在Windows下编程可能是Visual Studio ,在Linux下编程可能是GCC或LVM或者其他一些商用的编译器,那究竟要增加什么样的特性,C++才能更好用?要用什么样的标准来衡量“好用”?
他总结了两个点:C++一定要让应用能够非常好的利用硬件性能特性来提升硬件效能,同时更好的管控底层的编程复杂度。这两句话也很矛盾,高效利用硬件,像是某种形式的软硬结合。有效降低复杂度,是某种情况下的软硬解耦。同时,他也提出来一条原则,要能够让程序员写出好的代码,并创造出好的应用,而不是预防程序员出bug。一种是补补丁,一种是更好的牵引,来成就更好的开发者。
从这点让我们更加坚信AI芯片上的开发也需要充分释放硬件的性能,降低开发的复杂度,让AI开发者们在 AI芯片平台上开发自己最主要的应用,并把它变成一个很好的产品,推向客户、市场。结合C++ 14年的发展历史,我们认为这样的平台才是一个“好用”的开发平台。
03 用软件2.0基础设施、工具链、开放软件栈和丰富样例成就开发者
结合软件2.0的编程模式和编程范式,究竟应该怎么做才能做出一个好用的芯片、上层软件开发环境。在这方面地平线也在一直实践,所以下面将结合地平线的实践,从软件2.0的基础设施、工具链、开放软件栈和丰富样例几个层面来介绍一些相关的思考,我们也相信这可能是通往好用芯片,尤其是好用AI芯片、自动驾驶芯片,一定要走的路。
AI芯片需要一个工具链和软件2.0基础设施,在基础设施方面要有数据标注、模型训练平台,它可以支持算法开发和训练、算法评测、端到端的数据闭环,这样才能把更多的数据回传到基础设施里做数据驱动的软件2.0开发。而软件1.0经过40多年的时间已经变得非常成熟,我们在上面也会坚持做微创新。
另外一方面是模型部署优化和性能分析,AI算法放在芯片上运行起来时要很快、性能要好、精度要高,出问题后要知道怎样分析。当把算法用起来时是整套应用的开发,它最终会帮助开发者达到最终产品的目标。
首先讲下基础设施,这里会结合地平线艾迪AI开发工具平台的实践。艾迪AI开发工具平台是一个高效的软件2.0训练、测试、管理的工具平台。它由有几部分组成,比如在边缘侧有车、芯片,通过加密传输把数据传过来。在云端也是一套完整的基础设施,包括半/全自动的标注工具,自动化模型训练,长尾场景管理、软件自动集成、自动化回归测试,最后这整套模型通过OTA升级部署到芯片上。同时,在端上还有影子模式、量产相关的模型部署、功能安全和信息安全方面的工作。
这一整套工作不仅仅面向地平线的芯片,其他的芯片也一样,只是模型部署有所不同,但面向软件2.0的方法论都是一样的。开发者围绕关键场景的问题挖掘,模型迭代全流程的自动化,可以大幅改善算法的研发效率,而且可以开放的对接到各类的终端上面。通过这种方式,大大提升了算法研发人员的研发效率。

上图是根据算法人员研发效率做的初步分析和建模,得到了一些效率提升的数字来供大家做参考。比如数据挖掘,包括一些长尾数据管理和影子模式,在端上的影子模式像小朋友做考试题一样,一个小朋友做100道题,可能只错一道,但剩下的99道都没有什么用,关键的这一道题要放在我们的错题本上,持续的去温习、迭代。所以影子模式和长尾数据管理,都是AI模型非常宝贵的错题本。通过这种方式,数据上传和存储相关的效率会有很大的提升。
接下来是数据标注,原来是对所有的图片做标注。但在车辆实际运行过程中,它是一个时间和空间连续的状态,在连续的状态里,比如在两个不同的车道上,超一辆速度稍微低一些的车时,可能接下来的10秒内,车都在我的视野中,之后从视野里一点一点的消失。在这10秒范围内,如果按照1秒钟30帧去捕捉图片并标注,这会非常费时、费力。其实只需标注好一张图片,并利用时间和空间的连续性,可以实现自动化标注,甚至可以用自主学习方式训练一个大模型来做标注,标注完之后只需稍微校准下,就可以获得非常大标注效率的提升。
地平线艾迪平台上背后有一套与车上面的芯片和板子完全一致的设备集群,这套设备集群可以让每一个板子像车一样运行,只不过它在机房里,并且输入不是大街上采集的图片,而是一些回灌的视频图片,在上面我们做很多的探索,像AI模型的探索、编译架构的探索,也可以做很多应用代码的修改和回归调试,这大大地降低了整个设备、代码和软件算法测试的成本。
除此之外,还有Badcase管理系统, Badcase不仅仅是图片,还可能是某些输入,或是软件1.0、软件2.0在面向自动驾驶上的一些小case。
通过这些case的管理,能够更好的让算法开发者直接找到错题本,看怎么做来解决问题,大大提升的研发效率。经过这一整套研发效率的提升,可以更好的服务芯片上的产品开发。
接下来再讲下工具链和应用开发。如果大家有在英伟达平台上的开发经验,流程大概如下:先进行浮点模型训练,然后量化,看精度是否达标,如果不达标再做迭代,接下来模型编译放在平台上运行。地平线也很尊重开发者的开发习惯来做工具链和应用开发。
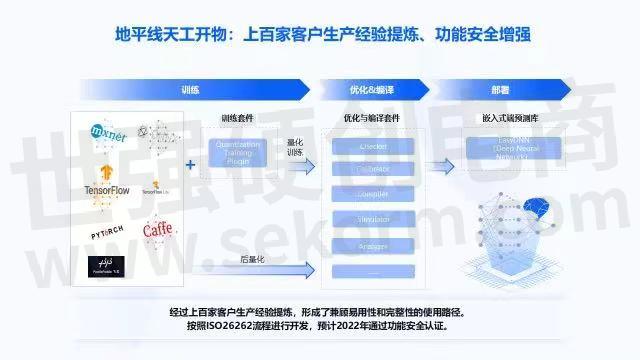
地平线天工开物已经服务了100多家客户,这100多家客户中的开发者,用这些工具、读这些文档、看这些例子,然后在基础上,把他们的想法、创造性发挥出来,遇到问题时去分析调试。
我们把他们看到的问题、想法,在发挥创造性上面遇到的阻碍,反过来帮助我们改进和提升天工开物工具链,这套千锤百炼的工具链就可以更好的提升效率。除此之外,因为是面向车,所以地平线也遵循着完整的ISO26262流程去做开发。在今年预计会完成整个功能安全的认证,让整套工具链交付给客户和开发者时,让他们更放心、更安全。
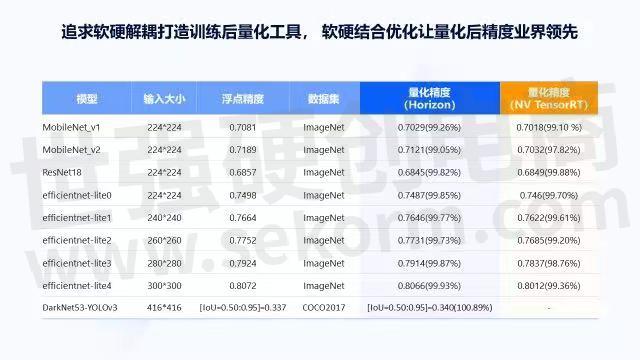
训练后量化工具也是一个很典型的软硬解耦工具,任何训练的符合规范要求的浮点模型,通过这个工具都可以部署在地平线芯片上。这个工具本身是一个软件,与芯片一起做了很多的联合优化,联合优化反过来可以提升量化精度,即经过量化工具的转换,不用做训练,它的精度的损失与英伟达量化后的精度对比如上图所示,可以看到量化的精度都是比英伟达量化后要好的。这是一个很典型的追求软硬解耦,同时通过软硬结合的方式,来打造一个对程序员和开发者更好用工具的过程。
在训练工具上,我们也有类似的创新,比如训练的Plugin,在优化和编译器方面也有很多相关的工具,它们都是来自于客户的宝贵建议和开发者的实际诉求。
在此基础上是一个非常丰富的软件栈,软件站里底层是OS,再底层是一些开发板,往上是一些软件和开发的参考方案。当各位拿到我们的芯片或工具时,它里面包含了一整套的工具链和开发组件,这些开发组件可以降低开发中的复杂度。与此同时,上面还会有很多的应用参考解决方案,以白盒或开源的方式提供给开发者。我们相信通过这些也可以大大提升开发者的效率,让开发者可以做出更好的产品,同时得到好用的效果。
总之,地平线在艾迪平台和天工开物上,包括了算法开发和应用、算法评测、端到端的数据闭环,AI算法部署,应用开发,诊断、调试、性能调优。这个过程都是面向开发者的,完全为开发者服务,而且是为开发者的产品研发效率服务。所以在这个过程中,一定要秉承开放、灵活、兼容,并且要做到高性能的原则。在这些原则的指引下,参考比较多的历史经验和教训,以史为鉴去看接下来怎么做来实现更好用的AI芯片开发工具。
上面讲了一个好用的开发工具,但它需要在市场上做相关的验证和迭代。当去看整个市场上的车载芯片时,我们发现中国尤其是国产的自主品牌,已经成为全球顶级汽车智能芯片和算法、计算平台的“角斗场”。比如2021年 Mobileye的EyeQ5,高通的Snapdragon Ride,英伟达的Xavier和Orin都是在国内自主品牌的自主车型上面首发,包括地平线征程3和征程5。
最后,再回顾下今天的内容,结合地平线的实践,我们正在做一个更好用的、世界一流的人工智能计算平台,它的目标是让开发者更好在上面开发基于AI的产品。包括旭日和征程芯片,芯片架构、编译器、SoC、AI算法、深度学习框架的技术交融,软硬协同优化,通过BPU微架构、版图、时序、片上网络、指令架构、运行调度、通信、功耗等方面提升性能和可靠性,流片验证,把它用在机器上,让机器像人一样可以看懂、听懂周围的世界。这点是保证了好用芯片里面软硬结合和软硬结合的核心。
除此之外,天工开物工具链沉淀了最领先的轻量化模型研发实践、模型压缩、量化训练、训练后量化、深度学习框架、运行时环境、AI应用方案到工具链中,通过自动化、工具化、样例化,服务万千开发者,普惠AI,让赋能机器更高效。
地平线的艾迪平台,通过端云协同、数据闭环、自动数据挖掘、自动化标注提升算法研发效率,通过评测集群和硬件在环测试提升边缘侧迭代效率。它背后还有一整套的硬件和评测集群,为了完成模型的训练,还要对GPU集群做管理,同时这些数据也要有存储管理,整个过程都要自动化高效调度。如果前面是为了提升算法的研发效率,后面就是为了提升硬件资源的利用率。
上面看到的是产品,产品背后是一整套的软件代码和基础架构。这包括怎么样写代码来实现高系统吞吐率、低延迟、高性能、低内存占用,并让系统正确且确定地运行的代码。从最基础芯片里的启动装载器,到芯片上的架构设计,架构设计上的汇编代码类似于张量指令代码,然后操作系统的驱动到内核,到编译器和Runtime的环境,再到深度学习框架、量化,这一整套的技术栈都是用代码一点点累积出来的。它还会用到多线程、高性能算法库、单核多线程、多核多线程、多SoC上的通讯调度、车规级的功能安全,这些方面都需要在软件层面考虑到。
- |
- +1 赞 0
- 收藏
- 评论 0
本文由天星转载自地平线,原文标题为:大牛讲堂 | 凌坤:好的自动驾驶AI芯片更是“好用”的芯片,本站所有转载文章系出于传递更多信息之目的,且明确注明来源,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
相关推荐

同芯共创 | 四方杰芯与中电超云签署战略合作协议
人工智能正成为推动各行各业转型的关键力量。它不仅改变了工作方式,更开辟了全新的业务模式。四方杰芯积极推动IC与AI的结合,布局算力服务器内的高精度电源、高速通讯的IC解决方案。四方杰芯与超云将以此次合作为新起点,不断挖掘合作潜力,拓展合作领域。在技术研发上共同攻坚,提升国产芯片的性能与稳定性,在数据中心建设中协同创新,打造高效、安全的解决方案。

地平线推出突破性能天花板的8MP前视感知方案,高效灵活地进行多类AI任务处理并实现实时检测与精准识别
地平线Mono系列是目前唯一实现前装量产的国产单目视觉ADAS方案,累计斩获十余款车型定点,Mono3 也成为全球首个量产级8MP前视感知方案。面向ADAS的规模化落地,地平线坚持定位Tier-2,通过提供征程芯片开放平台,持续以软硬协同。

2024高通汽车技术与合作峰会,与美格智能一起驭风前行
2024高通汽车技术与合作峰会将于5月30-31日在无锡国际会议中心举办。作为高通公司紧密的合作伙伴,美格智能将于5月30日下午举办“智慧启航,网联无限”2024高通汽车技术与合作峰会&美格智能分论坛,内容涵盖芯片A1、智能座舱、C-V2X、车端软件、自动驾驶等。

【应用】地平线AI SoC芯片X3ME00IBGTMB-H用于3D相机,集成四核Cortex A53 CPU
3D相机应用领域越来越广泛,除了常见的3D影片之外,还可以应用于物流自动化、机器人视觉、障碍检测等方面。3D相机是有两个镜头的,分别是用于拍摄场景和测量自身与场景内物体之间的距离。镜头获取信息需要一个强大芯片来处理,本文介绍一款SOC可用于3D相机上。


地平线旭日® X5 介绍
描述- 地平线公司作为智能驾驶计算方案提供商,专注于深度神经网络芯片研发。其产品征程系列和旭日系列芯片广泛应用于自动驾驶、智能驾驶辅助系统等领域。公司拥有150+车型前装定点,1000万+出货量,200+生态合作伙伴,1200+专利,1500+研发人员。地平线旭日芯片持续迭代,提供高效进化的智能平台,支持多种算法加速需求。旭日5芯片集成了CPU、BPU、GPU、DSP四合一异构加速,满足不同算法加速需求。

AI加速边缘计算,聚焦AIOT芯片,NPU SOC,离线语音MCU,高算力智能模组等
世强硬创联合地平线,阿普奇,启英泰伦,美格智能,普林芯驰,唯创知音,九芯电子,芯闻,VINKO,MERRY带来AI新产品,聚焦AIOT芯片,NPU SOC,离线语音MCU,高算力智能模组等,加速边缘计算。

【应用】地平线新一代AIoT AI SOC X3ME00IBGTMB-H成功用于AI分析盒子,提供5TOPS的算力
在盒子的主控方面,客户采用的是地平线的新一代AIoT AI SOC 旭日3系列X3ME00IBGTMB-H,这是地平线针对 AIoT 场景,推出的新一代低功耗、高性能的智能芯片,集成了地平线最先进的伯努利2.0 架构引擎( BPU® ),可提供5TOPS的算力。

【应用】地平线推出基于AI SoC X3M的扫地机方案,提供配套TROS操作系统和AI算法
地平线推出基于Sunrise®旭日芯片的扫地机方案,提供芯片+操作系统+算法的完整解决方案,实现更智能、更稳定、更主动的智能扫地机应用。

【应用】算力高达5TOPS的SOC X3ME00IBGTMB-H用于双目AI相机设计,满足输入图像的图像信号处理要求
某客户做一款双目AI相机,需要跑自己的识别算法,用于识别一些物体,算法是自研的,视频输出部分要求分辨率达到4K级别。在相机处理器上需要一款有一定算力和多路视频处理能力的芯片,客户采用地平线的旭日3系列AI SOC X3ME00IBGTMB-H,该款芯片性能强大,算力和视频处理能力均能满足需求。

罗森伯格液冷解决方案助力进阶的AI数据中心降低能耗焦虑
目前,针对功耗问题,推出了一种创新的光模块设计:LPO(Linear-drive Pluggable Optics)。这种设计通过取消传统的DSP和CDR芯片,在驱动芯片和跨阻放大器上分别集成连续时间线性均衡(CTLE)与均衡(EQ)功能,实现了低功耗、低成本和低延时的目标。这不仅简化了模块结构,提高了维护的便捷性,还支持热插拔功能。

【应用】地平线AI SoC芯片X3M助力智能停车场系统设计,可实现车牌识别、车流量检测等功能,算力可达5Tops
现在,随着智能芯片、算法的技术发展,方便快捷、稳定可靠的非接触式智能停车设备已走进大大小小的城市,成为当今停车场设备的主流。地平线推出的X3M系列AI SoC芯片,可应用于停车场的智能识别设备,用来检测施工车辆的车牌、类别,并可实现计算车流量的功能。

【产品】地平线天工开物AI开发平台OpenExplorer统一发布功能介绍
OpenExplorer,中文名称天工开物AI开发平台,是地平线AI芯片开放赋能的重要武器之一,主要由AI Toolchain工具链,AI Express应用开发中间件、AI Solution应用参考解决方案以及系统软件组成。

【应用】地平线AI SOC芯片X3M系列助力边缘计算盒子应用,算力可达5Tops
本文将介绍地平线X3M系列AI SOC芯片,可应用于边缘计算盒子,实现视觉部分的算法。镜头模组将采集到的信息传送给X3M芯片,芯片通过算法,实现视觉部分的识别,如人脸识别,手势识别,火焰识别的动作,然后将信息通过接口进行传输。

地平线提出MAPS评测方法,重新定义芯片AI性能
地平线作为边缘AI芯片领导者,长期致力于AI芯片的软硬件研发和商业落地工作。此次提出MAPS芯片AI性能评测方法,为行业提供一种在峰值算力之外,从“快”和“准”两个维度帮助用户理解芯片AI性能的角度。

电子商城

现货市场
服务
可支持TI AM335x/AM5718 和NXP iMX6/iMX8芯片定制核心板和计算单板;支持NXP iMX6核心模组X / F / H系列、TI AM335x核心模组X / N / H系列,与兼容的底板组合定制单板计算机。
最小起订量: 1pcs 提交需求>
世强深圳实验室提供Robei EDA软件免费使用服务,与VCS、NC-Verilog、Modelsim等EDA工具无缝衔接,将IC设计高度抽象化,并精简到三个基本元素:模块、引脚、连接线,自动生成代码。点击预约,支持到场/视频直播使用,资深专家全程指导。
实验室地址: 深圳 提交需求>
授权代理品牌:集成电路
























































授权代理品牌:分立元件






































授权代理品牌:接插件及结构件













授权代理品牌:部件、组件及配件




























授权代理品牌:电源及模块





授权代理品牌:电子材料














授权代理品牌:仪器仪表及测试配组件




授权代理品牌:电工工具及材料






授权代理品牌:机械电子元件








授权代理品牌:加工与定制












登录 | 立即注册
提交评论